Jiao-Hong Qiang , Gao Yang and Ding-Wan Ning
Green City Environmental Resource Monitoring and Privacy Protection Trust Evaluation Mechanism Based on Remote Sensing Network
Abstract: High-resolution remote-sensing-network technology has the advantages of low cost, accuracy, and real-time performance in green city environmental resource investigation and management. However, in the "Internet of everything," open, complex, and resource-intensive edge computing causes problems, such as equipment security issues and data leakage. Thus, the establishment of an effective trust evaluation mechanism has become an important research topic. In this study, the identity trust and behavioral trust of edge devices were combined, and a model was developed for evaluating the dynamic trust of edge devices. Through simulation analysis, the identity verification program has the advantages of good security performance and low bandwidth occupation, which increases the success rate of interaction with a device and enhances its data information security and privacy protection capabilities. Steps for the identity authentication process were identified, a trust evaluation mechanism was devised, and a privacy protection model was developed. Different indices were calculated to monitor environmental resources.
Keywords: Environmental Resource Monitoring , Privacy Protection , Remote-Sensing Network , Trust Evaluation
1. Introduction
Green cities play an important role in controlling the concentration of carbon dioxide and other greenhouse gases and in maintaining the balance of the ecosystem. However, while urbanization brings social and economic benefits to humankind, conflicts with the ecological environment are becoming increasingly obvious [1]. The rapid decline of green cities has led to the deterioration of the environment and climate [2]. Ultrahigh resolution remote sensing and the ability to provide more-refined data for classified information are already available [3]. They are widely used in the fields of environmental change monitoring, weather forecasting, and natural-resource exploration [4]. This technology has the advantages of low cost, accuracy, and real-time use in environmental resource investigation and the management of green cities [5]. This technology has been used to provide a theoretical basis for the sustainable development of forests [6]. The rapid development of cloud services has also forced people to pay increasing attention to the problem of device data leakages [7].
Therefore, the establishment of an effective trust-evaluation mechanism has become an important research topic. The main contributions of this study are as follows.
· For the study of forest quality status, remote-sensing-network technology and a forest resourcemonitoring system were combined to analyze the distribution pattern of forest resources in the study area.
· Evaluation and survey factors were combined, and a quality evaluation system was established for forest resources.
· Comprehensive research on data and ecological indicators provides technical support for scientific management of forest resources and ecological construction, promotes its vigorous development, and protects the ecological environment.
· An identity authentication process for terminal equipment nodes was developed.
The remainder of this article is organized as follows. In Section 2, related work is reviewed. In Section 3, the types of trust evaluation mechanism and data privacy protection method are analyzed. The privacy protection model, trust evaluation mechanism, and steps of the identity authentication process algorithms are described in Section 4. In Section 5, the simulation experimental results and analysis are presented. Section 6 provides the conclusion and possible future directions for this work.
2. Related Work
2.1 Research Overview
The topography and geomorphology of the study area include low mountains and hills, with a complete stratum. Geological movement has created many caves and large amounts of mineral resources [8]. In terms of climate, the study area has a subtropical monsoon climate, with hot summer temperatures and cold winter temperatures and four distinct seasons [9]. The air environment in the area is of superior quality, and the natural environment is beautiful and pleasant [10].
2.2 Theoretical Basis
In terms of spectral resolution, remote-sensing images have undergone a development process from panchromatic and multispectral images to hyperspectral images, and panchromatic images have been widely used in the field of early Earth observation [11]. They contain only a single spectral channel and spatial information of the features [12]. Currently, hyperspectral images are used to observe ground objects [13]. Hyperspectral remote sensing involves the use of hyperspectral sensors for data acquisition [14]. Visually, a hyperspectral remote-sensing image has a high-dimensional cubic appearance [15]. The image space of a hyperspectral image is a spatial feature suitable for specific band [16]. The attribute information of each pixel in the hyperspectral image can fit into a high-dimensional space [17]. Ding et al. [18] analyzed the application of remote-sensing technology to forest resource monitoring.
In terms of the data privacy protection of devices, the identity and trustworthiness of edge device behavior were employed in one study [19]. A terminal computing environment identity verification program based on a recognition algorithm was proposed [20]. It combines direct and indirect trust to gain trust in the behavior of a device [21]. The dynamic update factor was also used to update the reliability value of a behavior dynamically [22]. An effective trust evaluation mechanism was established based on the authentication results of the device identity and the reliability of the behavior [23]. Through simulation analysis, an identity verification program was found to have good security performance and low bandwidth occupation [24]. Wu et al. [25] suggested a deep differential privacy data protection algorithm based on a software-defined industrial network. Lai et al. [26] combined edge computing and federated learning to ensure model accuracy. In summary, this study provides a good theoretical basis for and demonstrated the technical feasibility of using remote-sensing networks to monitor environmental resources in green cities.
3. Analysis and Discussion
3.1 Analysis of Types of Trust Evaluation Mechanism
(1) Definition and classification of trust mechanism (Trust mechanism model): In all interactive environments, the node resources of the devices participating in the interaction are limited, and such technologies as intrusion detection, encryption, and password decoding are unsuitable for terminal devices with limited resources.
(2) Basic content and framework of dynamic trust mechanism: Identity trust determines whether the identity of a node in a trusted environment is based on a specific authentication protocol, encryption technology, digital signatures, or other technologies.
(3) Problem in the trust mechanism (Theoretical lag): In the field of reliable computers, research worldwide is lagging behind technical theoretical research. A reliable computer system is based on the measurement of certain models and their mechanisms.
3.2 Data Privacy Protection Methods
(1) Methods based on cryptography: The privacy protection method of cryptography encrypts the transmission and storage of sensitive user data and uses the encrypted data to perform specific data analysis operations to realize the still encrypted analysis results and decrypt the encrypted analysis results.
(2) Anonymity-based method: It is mainly used for structured data. The data are usually expressed as tables containing multiple records, with each record corresponding to the owner of the data. The attributes contained in the record can be divided into four categories: quasi-ID identifiers, ID identifiers, nonsensitive attributes, and sensitive attributes. The ID identifier can clearly identify the data owner.
(3) Disturbance-based methods: The basic idea of the disturbance-based method is to disrupt the original data while ensuring that the results obtained from the statistical analysis of the fault dataset are similar to those obtained from the statistical analysis of the original dataset.
3.3 Remote-Sensing Methods
There are three methods available: (1) automatic remote-sensing image monitoring (remote-sensing experiment), (2) manual interpretation, and (3) local verification.
The authors proposed the following:
The forest resource changes in XX County were analyzed using automatic sensing image monitoring and manual reading methods (Table 1).
Table 1.
| Interpretation of forest vegetation change area (hm2) | Number of interpretation patterns | Area of positive part (hm2) | Number of correct patterns | |
|---|---|---|---|---|
| Method 1 | 1,427.5867 | 118 | 1,059.3320 | 97 |
| Method 2 | 1,459.4637 | 126 | 1,033.0084 | 99 |
| Proposed method | 1,571.3586 | 132 | 1,176.2249 | 113 |
The correct rates of the number and area of the forest vegetation change map extracted by the remotesensing experiment method were 82.20% and 74.20%, respectively, the correct rates of the number and area of the forest vegetation change map extracted by the manual interpretation method were 78.57% and 70.78%, respectively, and the correct rates of the number and area of the forest vegetation change map extracted by the proposed method were 85.60% and 74.85%, respectively (Table 2). The accuracy of forest vegetation change patterns extracted by the remote-sensing experiment was 3.5 percentage points higher than for those extracted by manual interpretation. The accuracy of the forest vegetation change patterns extracted using the proposed method was 7.03 percentage points higher than that obtained using the manual interpretation method.
4. Privacy Protection Model, Trust Evaluation Mechanism, and the Steps of the Identity Authentication Process
4.1 Privacy Protection Model Construction
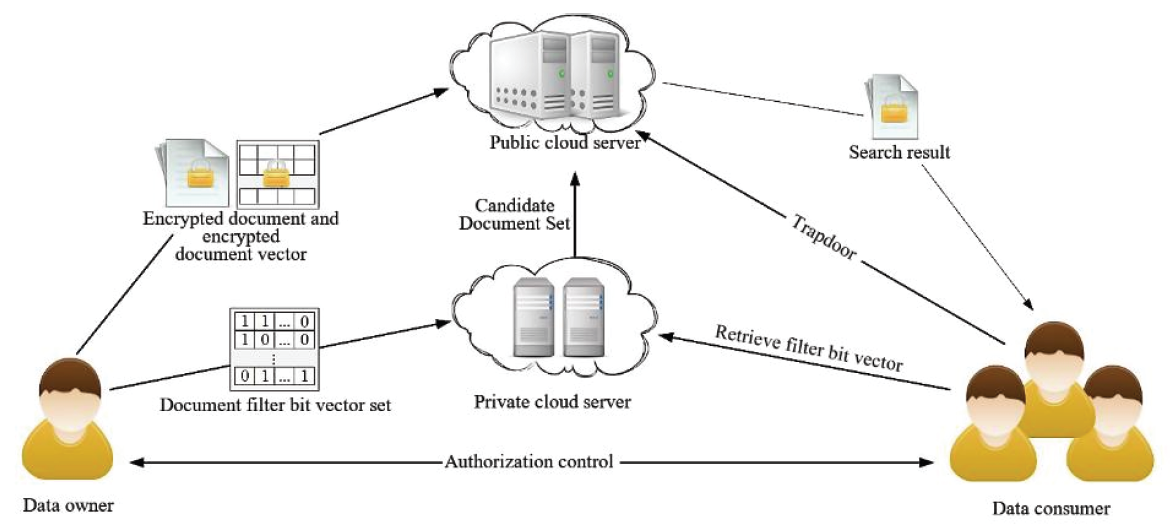
The general system model adopted has four main parts, as shown in Fig. 1.
Based on the background knowledge of Pub-Cloud, the known encrypted text model and the known background model are adopted. These two threat models help with the research analysis. The known encrypted text model Pub-Cloud only recognizes retrieval trapdoors and encrypted documents. It does not have plain text information about them.
4.2 Privacy Protection Trust Evaluation Mechanism
In an edge-computing environment, the edge-computing-layer devices in the cloud must be authenticated when they connect to the environment. The terminal only needs to perform identity verification on the edgecomputing device [27].
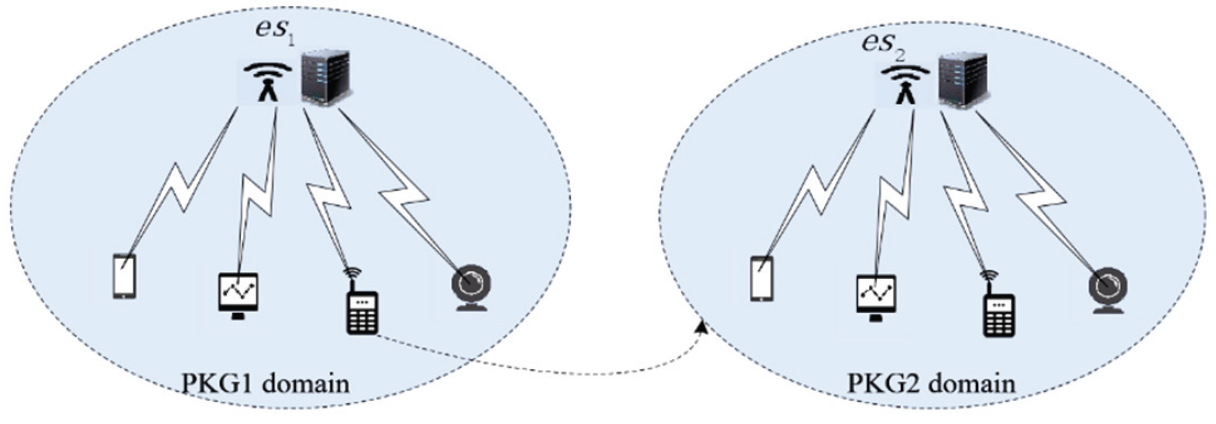
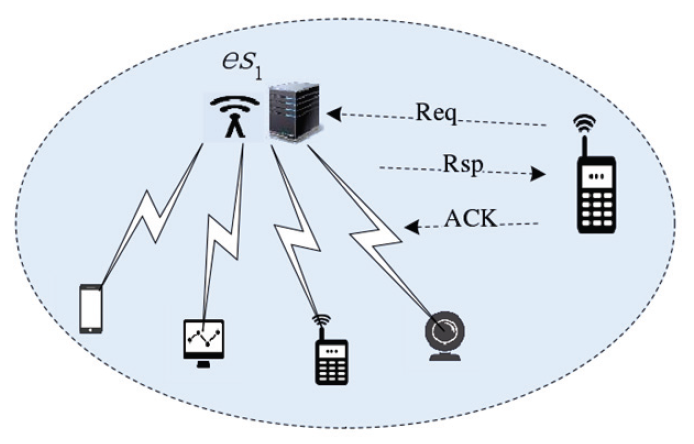
Single-domain terminal access authentication is shown in Fig. 2. Fig. 3 shows the terminal singledomain and cross-domain authentication diagram.
4.3 Identity Authentication Process for Terminal Equipment Nodes
The main steps of the identity authentication process for terminal equipment nodes are as follows.
When device [TeX:] $$\mathrm{ed}_{\mathrm{i}}$$ joins the network, it must perform identity authentication, send an authentication request to the edge-computing-layer node [TeX:] $$\mathrm{es}_1$$, obtain the corresponding key from the private-key generator, and apply it to the key communication of the session. The request sent by the device contains the identity of the device and the edge-layer node, as shown in Eq. (1):
(1)
[TeX:] $$\mathrm{ed}_{\mathrm{i}} \rightarrow \mathrm{es}_1: \text { AccessReq }\left\|\mathrm{N}_1\right\| \mathrm{ed}_{\mathrm{i}}\left\|\mathrm{es}_1\right\| \mathrm{h} \| \mathrm{S}$$After the identity authentication request from the terminal device is received, the SM9 signature algorithm is used to perform signature verification. After verification, the identity information of the terminal device is saved in the authentication list, and the encrypted authentication information is fed back to the terminal device node. First, the value of the [TeX:] $$\mathrm{Q}_{\mathrm{D}}$$ element in group [TeX:] $$\mathrm{G}_1$$ is calculated using Eq.(2):
(2)
[TeX:] $$\mathrm{Q}_{\mathrm{D}}=\left[\mathrm{H}_1\left(\mathrm{ed}_\mathrm{i} \| \text { hid, } \mathrm{N}\right)\right] \mathrm{P_1}+\mathrm{P}_{\text {pub-e }}$$The Cipher value in the group is calculated according to the generated random number r. Cipher is the ciphertext, where [TeX:] $$r \in[1, N-1].$$ Then, the encapsulated key Key is calculated according to Eq. (3), and the Key value is the edge shared key between the layer and the terminal device.
(3)
[TeX:] $$\text { Key }=\operatorname{KDF}\left(\text { Cipher }\left\|\left(\mathrm{P}_{\text {pub-e }}, \mathrm{P}_2\right)^{\mathrm{r}}\right\| \mathrm{D} \text {, klen }\right)$$The response identifier is requested, as in Eq. (4):
(4)
[TeX:] $$\mathrm{es}_1 \rightarrow \mathrm{ed}_{\mathrm{i}} \text { : AccessRsp || es}_1 \text { || Cipher || h || S }$$After the response from the node has been received, the Cipher content is accepted and parsed to obtain the relevant key Key. The first step is to judge Cipher and analyze whether it contains the elements in formula [TeX:] $$G_1.$$ If not, 0 is entered. If so, then [TeX:] $$\mathrm{w}^{\prime}$$ is calculated according to Eq. (5):
(5)
[TeX:] $$\mathrm{w}^{\prime}=\mathrm{e}\left(\text { Cipher, } \mathrm{d}_{\mathrm{ed} 1}\right)$$Then, SM9 is used to convert the data into a bit stream to calculate the response key Key, as shown in Eq. (6):
(6)
[TeX:] $$\text { Key }=\operatorname{KDF}\left(\text { Cipher }\left\|\mathrm{w}^{\prime}\right\| \text { ed }_{\mathrm{i}} \text {, klen }\right)$$If the key is 0, the identity authentication fails; otherwise, it succeeds. The identity in the node is saved as in Eq. (7):
(7)
[TeX:] $$\mathrm{ed}_{\mathrm{i}} \rightarrow \mathrm{es}_1 \text { : AccessAck || key }\left(\mathrm{ed}_{\mathrm{i}} \| \mathrm{es}_1\right)$$When the device moves to another domain, [TeX:] $$\mathrm{es}_2,$$ it sends a request for cross-domain authentication and encrypts the identity according to Eq. (8):
(8)
[TeX:] $$\mathrm{C}=\mathrm{E}_{\mathrm{key}_{-} \mathrm{old}}\left(\mathrm{ed}_{\mathrm{i}}\left\|\mathrm{es}_1\right\| \mathrm{es}_2\right)$$Reauth represents a cross-domain request, as in Eq. (9):
(9)
[TeX:] $$\mathrm{ed}_{\mathrm{i}} \rightarrow \mathrm{es}_2: \text { Reauth }\left\|\mathrm{ed}_{\mathrm{i}}\right\| \mathrm{es}_1\left\|\mathrm{es}_2\right\| \mathrm{C} \| \mathrm{N}_1$$The authentication information of the cross-domain terminal is derived jointly using [TeX:] $$\mathrm{es}_2 \text { and } \mathrm{es}_1 .$$ According to the [TeX:] $$\mathrm{r}_{\mathrm{es}_2}$$ generated by [TeX:] $$\mathrm{es}_2$$, [TeX:] $$\mathrm{G} * \mathrm{r}_{\mathrm{es}_2}$$ is calculated, and the data information is sent to [TeX:] $$\mathrm{es}_1,$$ as shown in Eq. (10):
(10)
[TeX:] $$\mathrm{es}_2 \rightarrow \mathrm{es}_1 \text { : KeyAgree } \|\left(\mathrm{ed}_1\left\|\mathrm{es}_2\right\| \mathrm{G} * \mathrm{r}_{\mathrm{s} 2}\|\mathrm{C}\| \mathrm{N}_2\right)_{\mathrm{PK}_{\mathrm{s} 1}}$$The more about identity authentication can refer to our previous work [28].
The SM9 signature algorithm is as follows.
Key generation algorithm:
1. KGC generates random number [TeX:] $$\mathrm{ks} \in[1, \mathrm{~N}-1]$$ as the signature master private key.
2. Calculate [TeX:] $$P_{\text {pub-s }}=[\mathrm{ks}] \mathrm{P}_2$$ signature master public key in [TeX:] $$\mathrm{G}_2$$
3. KGC calculates [TeX:] $$\mathrm{t}_1=\mathrm{H}_1\left(\mathrm{ID}_{\mathrm{A}}| | \text { hid, } \mathrm{N}\right)+\mathrm{ks}$$ on the finite field [TeX:] $$\mathrm{F}_\mathrm{N}.$$ If [TeX:] $$\\mathrm{t}_1=0,$$ start from step 1 again.
4. Calculate [TeX:] $$\mathrm{t}_2=\mathrm{ks} \cdot \mathrm{t}_1{ }^{-1} .$$
5. Calculate [TeX:] $$\mathrm{d}_{\mathrm{SA}}=\left[\mathrm{t}_2\right] \mathrm{P}_1$$ and sign the private key for the user.
Signature algorithm:
Assume message M to be signed.
1. Calculate g=e (P1, Ppub-s) in [TeX:] $$\mathrm{G}_\mathrm{T}$$
2. Generate random number [TeX:] $$\mathrm{r} \in[1, \mathrm{~N}-1]$$
3. Calculate [TeX:] $$\mathrm{W}=\mathrm{g}^{\mathrm{r}} \text { in } \mathrm{G}_{\mathrm{T}}$$ and convert W into bit string
4. Calculate [TeX:] $$\mathrm{h}=\mathrm{H}_2(\mathrm{M} \| \mathrm{W}, \mathrm{~N})$$
5. Calculate b=(r-h) mod N. If b=0, return step 2
6. Calculate s=[b] [TeX:] $$\mathrm{d}=\mathrm{SA}$$ in G1
7. Convert h into byte string, s into byte string, and M's signature is (h, s)
Verify signature algorithm:
Verify that the signer receives [TeX:] $$\mathrm{M}^{\prime} \text{ and } ( \mathrm{h}^{\prime}, \mathrm{s}^{\prime}),$$ and verify their correctness.
1. Convert [TeX:] $$\mathrm{h}^{\prime}$$ to an integer and verify whether [TeX:] $$\mathrm{h}^{\prime} \in[1, \mathrm{~N}-1]$$ is true. If not, the verification fails.
2. Convert s' to a point on the elliptic curve, and check whether [TeX:] $$\mathrm{s}\in \mathrm{G1}$$ is true. If not, the verification fails.
3. Calculate g=e [TeX:] $$\left(\mathrm{P}_1, \mathrm{P}_{\text {pub-s }}\right) \text { in } \mathrm{G}_{\mathrm{T}}$$
4. Calculate [TeX:] $$\mathrm{t}=\mathrm{g}^{\mathrm{h}^{\prime}} \text { in } \mathrm{G}_{\mathrm{T}}$$
5. Calculate [TeX:] $$\mathrm{h}_1=\mathrm{H}\left(\mathrm{ID}_{\mathrm{A}}| | \text { hid, } \mathrm{N}\right)$$
6. Calculate [TeX:] $$\mathrm{P}=\left[\mathrm{h}_1\right] \mathrm{P}_2+\mathrm{P}_{\text {pub-s}} \text{ in } \mathrm{G}_2$$
7. Calculate [TeX:] $$\mathrm{u}=\mathrm{e}\left(\mathrm{~S}^{\prime}, \mathrm{P}\right) \text { in } \mathrm{G}_{\mathrm{T}}$$
8. Calculate [TeX:] $$\mathrm{W}^{\prime}=\mathrm{u} \cdot \mathrm{t} \text { in } \mathrm{G}_{\mathrm{T}}$$ and convert W into bit string
9. Calculate [TeX:] $$\mathrm{h}_2=\mathrm{H}_2\left(\mathrm{M}^{\prime}| | \mathrm{W}^{\prime}, \mathrm{N}\right)$$ and check whether [TeX:] $$\mathrm{h}_2=\mathrm{h}^{\prime}$$ is true. If not, the verification fails.
5. Simulation Experimental Results and Analysis
5.1 Data Sources
In this study, second-class survey data from the study area in 2020 and Landsat images of the study area from 2004 to 2020 were used (receiving dates: October 10, 2020; August 12, 2016; October 4, 2012; October 25, 2008; October 30, 2004; and Google Earth images of the study area).
These remote-sensing image data show that the cloud amount in the current period is small, and the data quality is good, which are suitable for the requirements of this research.
5.2 Green City Environmental-Resource-Monitoring Classification Results
Verification samples were selected to evaluate the classification results. The accuracies of the various classification methods are listed in Table 3.
Table 3.
| Fuzzy classification | C5.0 decision tree method | Maximum-likelihood method | Artificial neural network | Support vector machine | |
|---|---|---|---|---|---|
| Overall accuracy (%) | 91.78 | 89.21 | 84.90 | 87.88 | 88.08 |
| Kappa coefficient | 0.82 | 0.75 | 0.81 | 0.83 | 0.83 |
Fuzzy classification has the best effect on the classification of building plots, followed by water and forest. The classification accuracy rate of the three land types exceeded 90%, and the classification accuracy rate of unused land was the worst. Some construction land and agricultural land were classified as unused plots, resulting in low production accuracy of unused plots. The C5.0 decision tree classification method had the best effect on water classification, followed by woodland and construction land. The production accuracy was lower than the fuzzy classification accuracy, but it was still higher than 90%. Similarly, the classification accuracy of unused land was the lowest, and the overall accuracy was better than that of fuzzy classification. Law is low. The support vector machine method had the highest accuracy rate among the three pixel-based methods, with an overall accuracy rate of 88.08%, followed by the artificial-neural-network method, with an overall classification accuracy rate of 87.88%. The maximum-likelihood method had the worst overall classification accuracy rate, with a total classification accuracy rate of 84.90%. The artificial neural network was second only to the support vector machine. It provided a good classification of construction land, unused land, and water areas, and the classification accuracy of agricultural areas and forests was low. When classified according to the maximum-probability method, the classification of unused building plots and forest plots was poor. The classification results for each image show that the maximum-likelihood method had a weak ability to explain the mountains in the image. The southern mountain forest land is divided into undeveloped land, construction land, and agricultural land. Consequently, construction land is larger than the unused land, and the other four types could distinguish the image spectrum more effectively. In image pixel classification, the salt-and-pepper phenomenon can be solved using the object-oriented method.
Object-oriented fuzzy classification was used to classify the images from 2012, 2016, and 2020 and obtain the effect picture (Figs. 4–6).
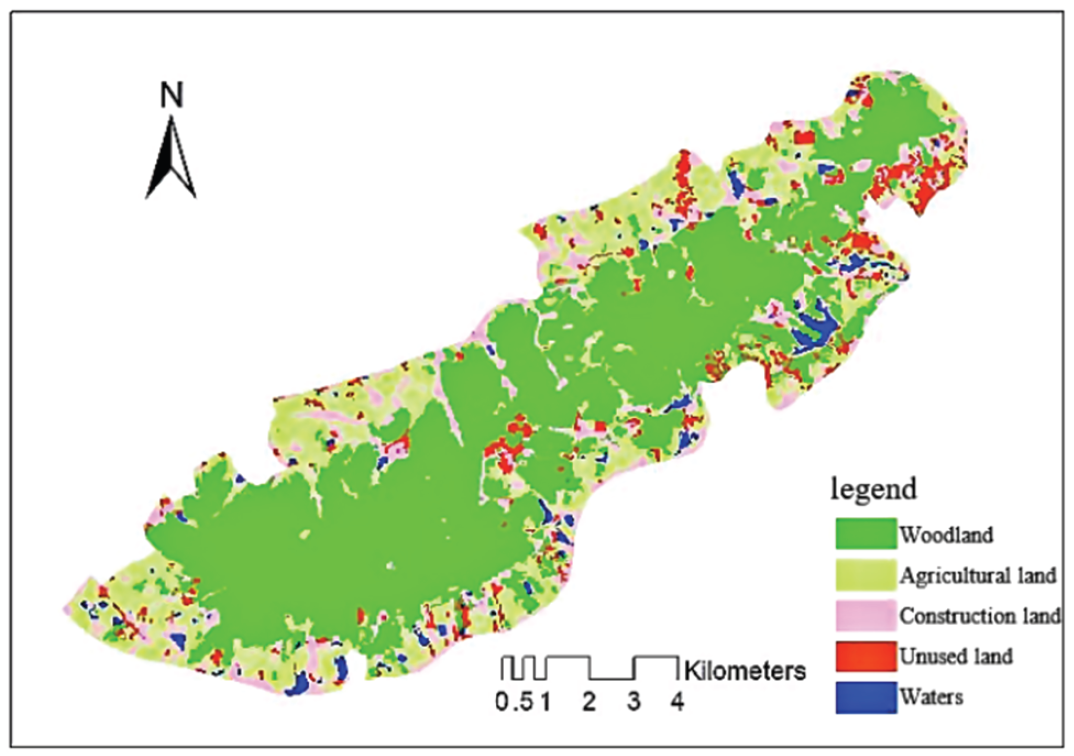
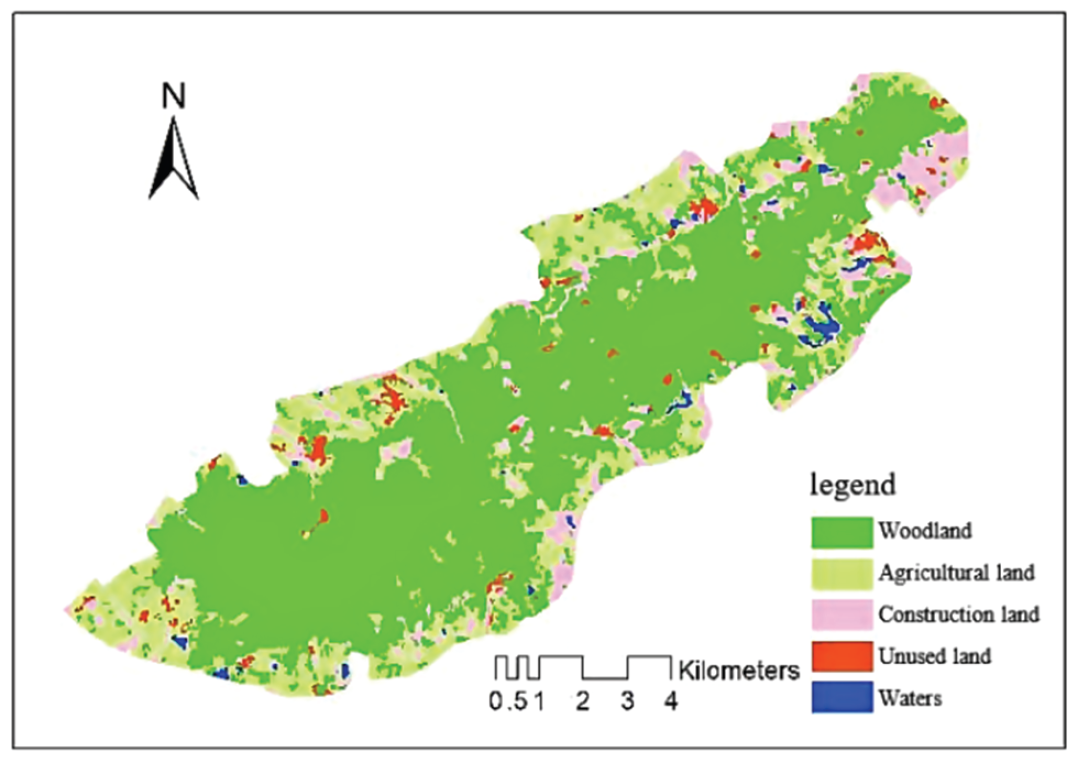
5.3 Results of Monitoring and Evaluation of Environmental Resources in Green Cities
Through the abovementioned research methods and steps, combining the forest quality evaluation standards and the data of the entire subclass in the study area, the qualities of 751 subclasses in the study area were evaluated.
Based on the distribution of small classes in different age groups, the area of middle-aged forests was the largest, accounting for half of the total area, followed by mature forests, and the area of overmature forests was the smallest. From the distribution of quality indicators, the average quality indicators of small classes increased with age. Because of the low canopy closure, small diameter at breast height, and imperfect ecological communities, the quality of young forests was low (Table 4).
As can be observed from the different types of small classes, the quality of coniferous forest is significantly lower than that of broad-leaved forest and coniferous and broad-leaved mixed forest, and the quality index is the lowest among all age groups. Coniferous forests have poor structure, poor stability, and slow natural succession. Forest communities composed of individual species of exotic pine and fir often suffer from pests and diseases, lack of forest care, and poor forest quality. Coniferous and broad-leaved mixed forests and broad-leaved forests are of higher quality. For young forests, the average quality index of broad-leaved forests is equivalent to those of coniferous and mixed coniferous and broadleaved forests. For the age-class near-mature forests, although the average quality index of the broadleaved forests is higher, the quality of the forests needs to be improved because of the invasion of other organisms and the clutter of shrubs. To address these problems, this index must be improved.
Table 4.
| Small class quality classification | Small class quality level | |||||
|---|---|---|---|---|---|---|
| Excellent [0.8, 0.9] | Good [0.7, 0.8) | Middle [0.6, 0.7) | Difference [0.5, 0.6) | Inferior [0.38, 0.5) | Total | |
| Total area (hm2) | 105.05 | 1546.08 | 3781.29 | 1362.92 | 218.73 | 7014.07 |
| Total area ratio (%) | 1.51 | 22.05 | 53.92 | 19.44 | 3.13 | 100.05 |
| Shelter forest (hm2) | 0 | 42.48 | 33.67 | 34.87 | 0.72 | 111.74 |
| Proportion of shelterbelt (%) | 0 | 38.03 | 30.15 | 31.22 | 0.64 | 100.04 |
| Special-purpose forest (hm2) | 105.05 | 1,502.94 | 3,612.45 | 1,301.79 | 186.49 | 6,708.72 |
| Proportion of special-purpose forest (%) | 1.58 | 22.5 | 53.86 | 19.41 | 2.79 | 1,000.14 |
| Timber forest (hm2) | 0 | 0.78 | 23.64 | 23.75 | 30.27 | 78.44 |
| Proportion of timber forest (%) | 0 | 0.98 | 30.15 | 30.28 | 38.61 | 100.02 |
| Economic forest (hm2) | 0 | 0 | 111.78 | 2.63 | 1.28 | 115.69 |
| Proportion of economic forest (%) | 0 | 0 | 96.63 | 2.27 | 1.12 | 100.02 |
The average qualities of the age groups from the different sources were compared. The data show that there is a gap between the forest quality indicators of natural and planted forests. Among the middleaged, mature, and near-mature forests, there are more natural forests, and the average forest quality index is approximately 0.35 higher. The quality indices of these two forests showed the same changing trend as the age group and gradually increased with the growth of the age group. The area of overmature forests is small, and all of them are plantations. Because the number of cultivated natural forests in the study area is relatively limited, the total area of immature forests is small. Field studies have shown that plantations have advantages in terms of tree height at breast height. However, because of their poor stand structure, they are more susceptible to pests and diseases. Therefore, it is important to focus on improving the forest structure in the management process.
This study involved a simulation of the study area forest quality evaluation index built on a small class scale. As a result of this research, a standard is proposed for small-scale forest quality evaluation based on previous research results and the actual situation of the study area. Sixteen factors are selected as evaluation indicators. The analytic hierarchy process is used to determine the index weight. The weight grade of the quality evaluation index of the small class is obtained, the data are analyzed, and the method of equidistant grouping is used to divide the forest quality evaluation index standards of the study area into poor, poor, medium, good, and excellent. In this study, the quality of the forest subgroups in the study area was evaluated to obtain the overall quality distribution of the study area, and the forest status and quality defects in the study area were analyzed from different angles. The landscape pattern index was combined with small class survey factors to evaluate the quality of forest resources comprehensively. A more intuitive understanding of the quality of forest resources in the study area, based on data and extensive monitoring, demonstrates the technical feasibility.
The weight of the recommended equipment is calculated by the traditional gray correlation method and typical entropy method. The test results are listed in Table 5. More information about weight allocation can be found elsewhere [29].
Table 5.
| Parameter | Description | Value |
|---|---|---|
| n | Total number of edge devices | 1001 |
| Deployment area | Deployment range (m2>) | 501 × 501 |
| T | Trust initial value | 0.4 |
| r | Communication radius | 21 |
| ρ | Reward factor | 0.3 |
| θ | Penalty factor | 0.6 |
| [TeX:] $$\alpha_0$$ | Dynamic update factor initial value | 0.4 |
The weight is a crucial factor affecting the results. Table 6 shows that the proposed method has a value of 0.107, which is almost the same as that of the second method, whereas that of the third method has a value of 0.518, which differs from both the proposed method and the weight value generated by the second method. The proposed method is more accurate than the other two methods, and the recommended device weight is more in line with the objective facts.
Table 6.
| Method type | Recommended device weight | ||||||
|---|---|---|---|---|---|---|---|
| [TeX:] $$\mathrm{W}_1$$ | [TeX:] $$\mathrm{W}_2$$ | [TeX:] $$\mathrm{W}_3$$ | ... | [TeX:] $$\mathrm{W}_8$$ | [TeX:] $$\mathrm{W}_9$$ | [TeX:] $$\mathrm{W}_10$$ | |
| Method of this article | 0.107 | 0.093 | 0.097 | ... | 0.113 | 0.082 | 0.148 |
| Canonical entropy method | 0.102 | 0.106 | 0.095 | ... | 0.084 | 0.093 | 0.118 |
| Traditional gray relation method | 0.518 | 0.688 | 0.772 | ... | 0.746 | 0.688 | 0.872 |
6. Conclusion
Although urbanization has brought social and economic benefits, the ecological environment has been severely damaged. The area of forests, which are the "lungs" of the earth, has been reduced drastically, resulting in a decline in the ability to purify natural air and aggravating the impact on human production and life. In this study, high-resolution remote-sensing-network technology was employed, using an application program for forest resource monitoring and ecological landscape evaluation to obtain a realtime understanding of forest resource dynamics and to raise the level of forest environmental resource monitoring to a new level. In the Internet of everything, edge computing is open, with the characteristics of complexity and resource constraints, leading to such problems as equipment security and environmental data leakage. By combining the identity credibility and trust behavior of edge devices, a dynamic model was developed for evaluating the reliability of edge devices. Creating a reliability mechanism scheme with good security and low bandwidth overhead not only increases the success rate of interaction between devices but also strengthens data security and privacy capabilities and promotes vigorous development.

Biography

Biography

References
- 1 R. Mukherjee, D. Sengupta, and S. K. Sikdar, "Sustainability in the context of process engineering," Clean Technologies and Environmental Policy, vol. 17, pp. 833-840, 2015. https://doi.org/10.1007/s10098-0150952-7doi:[[[10.1007/s10098-0150952-7]]]
- 2 N. V ahabzadeh Najafi, A. Arshadi Khamseh, and A. Mirzazadeh, "An integrated sustainable and flexible supplier evaluation model under uncertainty by game theory and subjective/objective data: Iranian casting industry," Global Journal of Flexible Systems Management, vol. 21, pp. 309-322, 2020. https://doi.org/10.100 7/s40171-020-00250-wdoi:[[[10.1007/s40171-020-00250-w]]]
- 3 S. M. Nourbakhsh, Y . Bai, G. D. Maia, Y . Ouyang, and L. Rodriguez, "Grain supply chain network design and logistics planning for reducing post-harvest loss," Biosystems Engineering, vol. 151, pp. 105-115, 2016. https://doi.org/10.1016/j.biosystemseng.2016.08.011doi:[[[10.1016/j.biosystemseng.2016.08.011]]]
- 4 E. Pagone, M. Jolly, and K. Salonitis, "The development of a tool to promote sustainability in casting processes," Procedia CIRP, vol. 55, pp. 53-58, 2016. https://doi.org/10.1016/j.procir.2016.09.001doi:[[[10.1016/j.procir.2016.09.001]]]
- 5 E. Pagone, K. Salonitis, and M. Jolly, "Energy and material efficiency metrics in foundries," Procedia Manufacturing, vol. 21, pp. 421-428, 2018. https://doi.org/10.1016/j.promfg.2018.02.140doi:[[[10.1016/j.promfg.2018.02.140]]]
- 6 R. K. Panda and Sreekumar, "Marketing channel choice and marketing efficiency assessment in agribusiness," Journal of International Food & Agribusiness Marketing, vol. 24, no. 3, pp. 213-230, 2012. https://doi.org/10.1080/08974438.2012.691812doi:[[[10.1080/08974438.2012.691812]]]
- 7 D. Paraskevas, G. Ingarao, Y . Deng, J. R. Duflou, Y . Pontikes, and B. Blanpain, "Evaluating the material resource efficiency of secondary aluminium production: a Monte Carlo-based decision-support tool," Journal of Cleaner Production, vol. 215, pp. 488-496, 2019. https://doi.org/10.1016/j.jclepro.2019.01.097doi:[[[10.1016/j.jclepro.2019.01.097]]]
- 8 M. M. Siddh, G. Soni, R. Jain, M. K. Sharma, and V . Yadav, "Agri-fresh food supply chain quality (AFSCQ): a literature review," Industrial Management & Data Systems, vol. 117, no. 9, pp. 2015-2044, 2017. https://doi.org/10.1108/IMDS-10-2016-0427doi:[[[10.1108/IMDS-10--0427]]]
- 9 G. Sihariya, V . B. Hatmode, and V . Nagadevara, "Supply chain management of fruits and vegetables in India," International Journal of Operations and Quantitative Management, vol. 19, no. 2, pp. 113-122, 2013.custom:[[[-]]]
- 10 S. K. Sikdar, D. Sengupta, and P. Harten, "More on aggregating multiple indicators into a single index for sustainability analyses," Clean Technologies and Environmental Policy, vol. 14, pp. 765-773, 2012. https://doi.org/10.1007/s10098-012-0520-3doi:[[[10.1007/s10098-012-0520-3]]]
- 11 V . Sohoni and A. Joshi, "Nisarg Nirman: the social farming venture from India," Emerald Emerging Markets Case Studies, vol. 5, no. 8, pp. 1-15, 2015. https://doi.org/10.1108/EEMCS-03-2015-0053doi:[[[10.1108/EEMCS-03--0053]]]
- 12 C. Tian and J. Peng, "An integrated picture fuzzy ANP-TODIM multi-criteria decision-making approach for tourism attraction recommendation," Technological and Economic Development of Economy, vol. 26, no. 2, pp. 331-354, 2020. https://doi.org/10.3846/tede.2019.11412doi:[[[10.3846/tede.2019.11412]]]
- 13 A. C. Tolga, I. B. Parlak, and O. Castillo, "Finite-interval-valued Type-2 Gaussian fuzzy numbers applied to fuzzy TODIM in a healthcare problem," Engineering Applications of Artificial Intelligence, vol. 87, article no. 103352, 2020. https://doi.org/10.1016/j.engappai.2019.103352doi:[[[10.1016/j.engappai.2019.103352]]]
- 14 A. Trebbin, "Linking small farmers to modern retail through producer organizations: experiences with producer companies in India," Food Policy, vol. 45, pp. 35-44, 2014. https://doi.org/10.1016/j.foodpol.2013.12.007doi:[[[10.1016/j.foodpol.2013.12.007]]]
- 15 S. J. Walters, Quality of Life Outcomes in Clinical Trials and Health-Care Evaluation: A Practical Guide to Analysis and Interpretation. Chichester, UK: John Wiley & Sons, 2009. https://doi.org/10.1002/9780470840 481doi:[[[10.1002/9780470840481]]]
- 16 C. Y ue, "An interval-valued intuitionistic fuzzy projection-based approach and application to evaluating knowledge transfer effectiveness," Neural Computing and Applications, vol. 31, pp. 7685-7706, 2019. https://doi.org/10.1007/s00521-018-3571-5doi:[[[10.1007/s00521-018-3571-5]]]
- 17 D. Zindani, S. R. Maity, S. Bhowmik, and S. Chakraborty, "A material selection approach using the TODIM (TOmada de Decisao Interativa Multicriterio) method and its analysis," International Journal of Materials Research, vol. 108, no. 5, pp. 345-354, 2017. https://doi.org/10.3139/146.111489doi:[[[10.3139/146.111489]]]
- 18 L. Ding, T. Sun, Z. Gao, F. Meng, Q. li, J. Luo, and Y . Zhao, "Study on forest resources monitoring method based on remote sensing technology," Agricultural Science, vol. 1, no. 1, pp. 85-86, 2021. https://doi.org/10.1 2238/as.v4i1.1972doi:[[[10.12238/as.v4i1]]]
- 19 M. Rahimi, A. Baboli, and Y . Rekik, "Multi-objective inventory routing problem: a stochastic model to consider profit, service level and green criteria," Transportation Research Part E: Logistics and Transportation Review, vol. 101, pp. 59-83, 2017. https://doi.org/10.1016/j.tre.2017.03.001doi:[[[10.1016/j.tre.2017.03.001]]]
- 20 S. K. Rajak, A. Aherwar, D. R. Unune, M. Mia, and C. I. Pruncu, "Evaluation of copper-based alloy (C93200) composites reinforced with marble dust developed by stir casting under vacuum environment," Materials, vol. 12, no. 10, article no. 1574, 2019. https://doi.org/10.3390/ma12101574doi:[[[10.3390/ma1574]]]
- 21 A. Rong, R. Akkerman, and M. Grunow, "An optimization approach for managing fresh food quality throughout the supply chain," International Journal of Production Economics, vol. 131, no. 1, pp. 421-429, 2011. https://doi.org/10.1016/j.ijpe.2009.11.026doi:[[[10.1016/j.ijpe.2009.11.026]]]
- 22 S. Routroy and A. Behera, "Agriculture supply chain: a systematic review of literature and implications for future research," Journal of Agribusiness in Developing and Emerging Economies, vol. 7, no. 3, pp. 275-302, 2017. https://doi.org/10.1108/JADEE-06-2016-0039doi:[[[10.1108/JADEE-06--0039]]]
- 23 K. Salonitis, M. Jolly, E. Pagone, and M. Papanikolaou, "Life-cycle and energy assessment of automotive component manufacturing: the dilemma between aluminum and cast iron," Energies, vol. 12, no. 13, article no. 2557, 2019. https://doi.org/10.3390/en12132557doi:[[[10.3390/en1557]]]
- 24 M. V . Samuel, M. Shah, and B. S. Sahay, "An insight into agri-food supply chains: a review," International Journal of V alue Chain Management, vol. 6, no. 2, pp. 115-143, 2012. https://doi.org/10.1504/IJVCM.2012.0 48378doi:[[[10.1504/IJVCM.2012.048378]]]
- 25 W. Wu, Q. Qi, and X. Y u, "Deep learning-based data privacy protection in software-defined industrial networking," Computers and Electrical Engineering, vol. 106, article no. 108578, 2023. https://doi.org/10.10 16/j.compeleceng.2023.108578doi:[[[10.1016/j.compeleceng.2023.108578]]]
- 26 J. Lai, X. Song, R. Wang, and X. Li, "Edge intelligent collaborative privacy protection solution for smart medical," Cyber Security and Applications, vol. 1, article no. 100010, 2023. https://doi.org/10.1016/j.csa.202 2.100010doi:[[[10.1016/j.csa.2022.100010]]]
- 27 H. Jiao, X. Wang, and W. Ding, "Service oriented cloud computing trusted evaluation model," Journal of Information Processing Systems, vol. 16, no. 6, pp. 1281-1292, 2020. https://doi.org/10.3745/JIPS.03.0153doi:[[[10.3745/JIPS.03.0153]]]
- 28 J. Tian, H. Jiao, N. Li, and T. Liu, "Double secret keys and double random numbers authentication scheme," Journal of Computer Research and Development, vol. 45, no. 5, pp. 779-785, 2008.custom:[[[-]]]
- 29 H. Jiao, W. Ding, Y . Shi, N. Zhao, and B. Wang, "Supply chain risk assessment model based on cloud model with subjective preference weight allocation algorithm," Intelligent Decision Technologies, vol. 14, no. 2, pp. 133-142, 2020. https://doi.org/10.3233/IDT-180001doi:[[[10.3233/IDT-180001]]]