Jinah Kim and Nammee Moon*
User-to-User Matching Services through Prediction of Mutual Satisfaction Based on Deep Neural Network
Abstract: With the development of the sharing economy, existing recommender services are changing from user–item recommendations to user–user recommendations. The most important consideration is that all users should have the best possible satisfaction. To achieve this outcome, the matching service adds information between users and items necessary for the existing recommender service and information between users, so higher-level data mining is required. To this end, this paper proposes a user-to-user matching service (UTU-MS) employing the prediction of mutual satisfaction based on learning. Users were divided into consumers and suppliers, and the properties considered for recommendations were set by filtering and weighting. Based on this process, we implemented a convolutional neural network (CNN)–deep neural network (DNN)-based model that can predict each supplier’s satisfaction from the consumer perspective and each consumer’s satisfaction from the supplier perspective. After deriving the final mutual satisfaction using the predicted satisfaction, a top recommendation list is recommended to all users. The proposed model was applied to match guests with hosts using Airbnb data, which is a representative sharing economy platform. The proposed model is meaningful in that it has been optimized for the sharing economy and recommendations that reflect user-specific priorities.
Keywords: Convolutional Neural Network (CNN) , Deep Learning , Deep Neural Network (DNN) , Matching Service , Recommender Service
1. Introduction
Recommender systems have already been widely applied in daily life and various recommender applications have been developed. In particular, as mobile devices have become popular, the real-time accumulation of user data has become easier and recommender systems have been developed based on big data [1-3]. Thus, personalized recommender services have become more intelligent [4-8].
Most general recommender systems use user–item recommender systems such as content-based filtering, collaborative filtering, and hybrid collaborative filtering [9-12]. However, with the development of shared economy-based businesses (Airbnb, Uber Taxi, etc.), new systems are starting to differ from existing recommender services.
Currently, consumers may still appear to be recommended specific items; however, when purchasing an item, consumers can now start considering their supplier. In other words, the presence of suppliers has begun to be integrated into items, and the supplier–consumer relationship has become important. Rather than simply purchasing items, suppliers and consumers choose each other; thus, beyond item recom¬mendations to consumers, mutual recommendations suitable for consumers and suppliers are required.However, consumer-oriented recommender service research has primarily focused on the consumers’ item selection rather than suppliers. These services are unidirectional in their recommendations of items to consumers and recommendations are made with consumer- and item-related information. For mutual recommendation, information about the supplier is added to the data, which increases the data and the calculations become more complicated. However, this step is very important in the sharing economy platform because it can increase satisfaction for all users.
Mutual recommendations of consumers and suppliers first require an understanding of each user’s situation and preferences. For example, the consumer data for Airbnb can include the location, date, and number of people that wish to stay, and the supplier data can include the consumer’s number of nights. As such, the characteristics desired by the consumer from the supplier differ from those desired by the supplier from the consumer, so modeling the overall situation is difficult.
In this paper, we propose a matching service that predicts mutual satisfaction between users. Here, “users” refers both to consumers who purchase items and suppliers who provide items, and consumers and suppliers are matched together. To this end, we derive the required property variables from the perspective of consumers and suppliers; based on these variables, the satisfaction from each user is derived using two deep neural network (DNN) models. Finally, we propose matching to users by calculating the mutual satisfaction between consumers and suppliers.
This paper is organized as follows: Section 2 discusses existing studies, Section 3 describes our proposed method and Section 4 describes the process used to generate mutual satisfaction. Section 5 analyzes existing research and compares it with our proposed method. Finally, Section 6 presents conclusions and future research.
2. Related Works
Recommender services are largely divided into collaborative filtering and content-based filtering. Among them, collaborative filtering is a method of recommending items to other users with similar preferences. Content-based filtering is a method for determining and recommending items that a user may prefer with similar characteristics to previously preferred items. Since collaborative filtering is a good algorithm in that it produces a variety of results rather than the same result, it has been used as a basis in many studies [13,14]. Memory-based collaborative filtering is commonly used and is divided into user-based filtering, which recommends items with high similarity to other users, and item-based filtering, which recommends items with high similarity to recommended items. Various studies have predicted and recommended preferences by calculating similarity using various data types such as social relations and location [15-17].
However, as data grows in size and complexity, a larger amount of computation is required and systems have changed to neural network-based recommendations—convolutional neural network (CNN), recurrent neural network (RNN), etc. [18]. Unlike existing recommender services, the accurate prediction of preferences is possible through efficient weighted learning between users, and various studies are being conducted in this field. Fu et al. [7] proposed a new collaborative filtering model based on deep learning that can predict ratings by learning low-dimensional embeddings for both users and items and by using multi-view feedforward neural networks. Liu et al. [8] proposed a recommendation DNN framework based on deep reinforcement learning. Unlike previous studies, this study confirms that the recommen¬dation performance is improved by explicitly modeling dynamic user–item interactions based on reinforcement learning. Most previous studies suggest recommendations between learning-based user–items according to the data’s features.
Research on matching services for user–user recommendations has also been ongoing. Xia et al. [19] proposed a partner recommender system for online dating sites based on the similarity between users’ messages and attractiveness, and Kacchi and Deorankar [20] proposed a friend recommender system based on users’ lifestyles in social network services (SNS). Most of these matching recommender services only differ in terms of users’ inclination and are equal without distinguishing user roles. Therefore, there is no difference in what feature factors should be considered for each user.
However, the latest trend is the sharing economy, which differs from the previous business. The sharing economy refers to economic activities in which items are rented to various users rather than owned. Various sharing economy platforms such as Airbnb, Uber Taxi, and Zipcar are being used worldwide [21]. One characteristic of these platforms is that users’ roles are generally divided into consumers and suppliers. Since items are limited due to the nature of “sharing,” various suppliers may exist for one item or similar items. In the existing recommender service, as shown in Fig. 1(a), consumers simply selected and were recommended items. In the recommender service based on the shared economy, shown in Fig. 1(b), consumers are recommended both items and suppliers, which becomes a factor in consumers’ purchasing decisions. In addition, if many consumers make purchase requests, suppliers can choose their consumer.
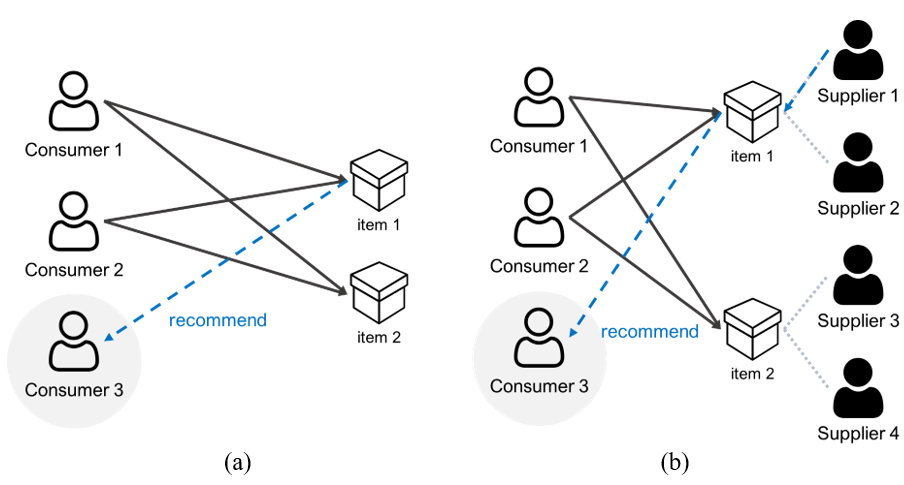
Most research in this area has focused on consumers and suppliers among various multi-stakeholders [22], and various aspects such as multi-stakeholder pattern analysis and recommendation algorithms are in progress [23,24]. However, there is a lack of research on consumer–supplier matching services suitable for consumption trends in the “shared economy” [25]. To this end, this paper proposes a user matching-related study suitable for consumption trends in the sharing economy. At this time, we propose a matching recommendation method based on deep learning because information about suppliers is added to grow the dataset.
3. User-to-User Matching Service
In this paper, we propose a user-to-user matching service (UTU-MS) that can be used in a sharing economy. At this time, various multi-stakeholders may exist depending on the shared economic platform, but this paper only distinguishes consumers who want to purchase items and suppliers who provide such items.
One important consideration when matching consumers to suppliers is that they have disparate recommendation priorities. Therefore, it is necessary to consider each group’s recommendation priorities separately. To this end, in this paper, we derive the properties preferred by each group and predict the satisfaction of suppliers from the consumer’s perspective and the satisfaction of consumers from the supplier’s perspective. Then, we propose a UTU-MS that satisfies both groups and derives mutual satisfaction by combining the two preferences. As shown in Fig. 2, the process includes setting user-specific properties, predicting user-specific satisfaction, and deriving mutual satisfaction.
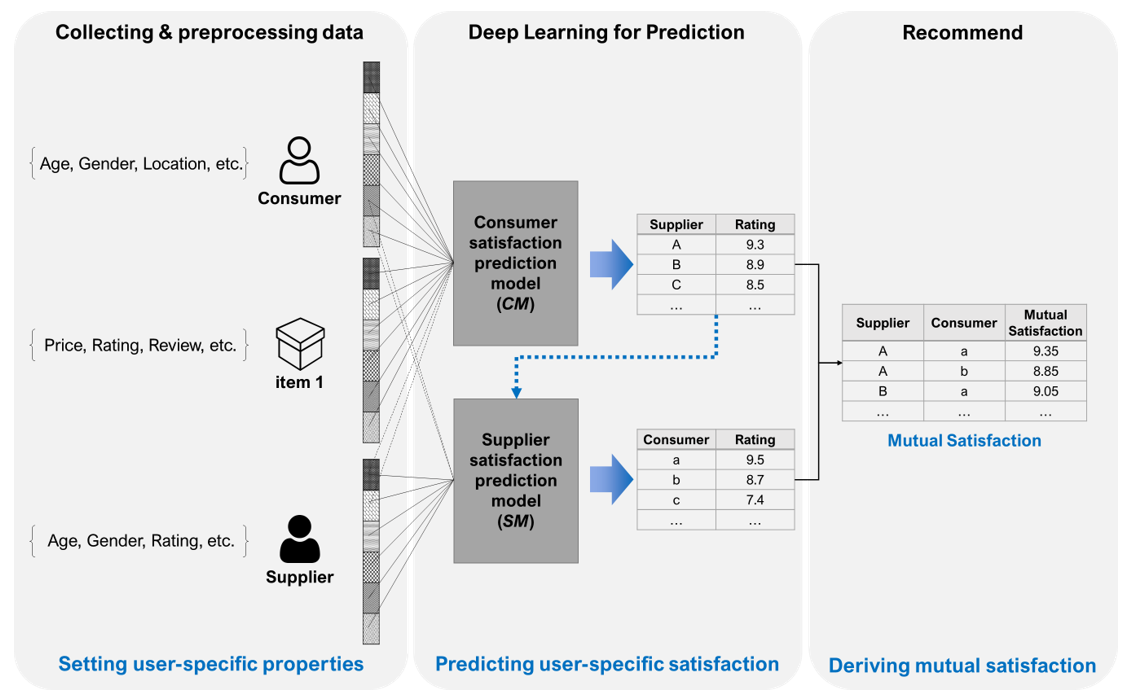
First, setting user-specific properties is a process that involves selecting necessary data for consumers, suppliers, and items to extract satisfaction as well as collecting and preprocessing these groups according to each data. During this process, property selection is performed for each data to select only necessary data. The next step involves predicting satisfaction based on the collected data. This process consists of two deep neural network models. One is a model (CM) that predicts consumer satisfaction with suppliers, and the other (SM) predicts supplier satisfaction with consumers. Since the supplier does not need to predict satisfaction for all consumers, the SM performs satisfaction prediction only for consumers with high purchasing probability according to the prediction results derived from the CM. Mutual satisfaction is derived using the user-specific satisfaction predicted by the CM and SM, and, finally, a top recommendation list based on this process is generated and proposed to the user.
4. UTU-MS Process
4.1 The Artificial Image Dataset Experiments
Before extracting mutual satisfaction, each user has different priorities (consumer, supplier), so it is necessary to set properties for deriving mutual satisfaction. Therefore, it is necessary to understand the purchasing process from the point of view of consumers and suppliers.
Assume that Consumer 1 and Consumer 2 want to purchase Item 1, as shown in Fig. 3. The existing recommender service would result in both consumers choosing Item 1, but the model proposed in this paper adds a process that selects a supplier to sell Item 1 since it is a recommender service model based on the sharing economy. Using Airbnb as an example, when a consumer is looking for accommodation in Area A, Item 1 could be an accommodation location in Area A, and the suppliers are those who provide accommodation in Area A. In addition, Item 1 may be subject to specific conditions such as accom¬modation for more than four people in the A area. The item setting may vary depending on the platform to which it is applied. After selecting Item 1, which is an accommodation in Area A, the consumer selects a supplier that provides Item 1 that satisfies their priorities. This selection may be performed based on the ratings of users who chose different accommodations or the style of the host.
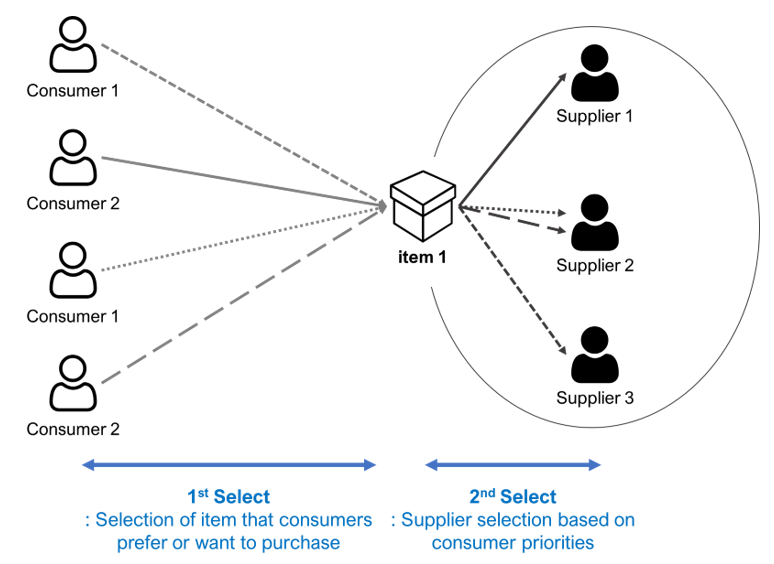
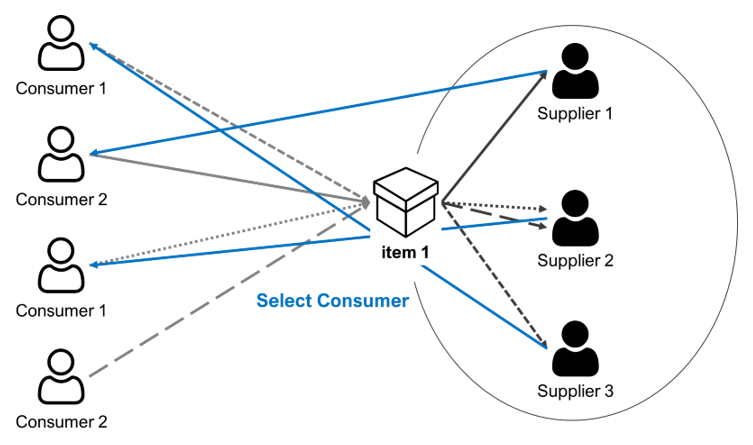
On the other hand, since the item to be sold is already determined from the supplier’s point of view, it is not necessary to select the item; in that case, a selection is made from among consumers who wish to purchase the item provided. In general, as in the case of Supplier 1 and Supplier 3 in Fig. 4, most consumers are selected without any special evaluation or condition. However, since items are limited in the shared economy, the consumer may be selected, as in the case of Supplier 2, or rejected if they are rude, depending on the platform.
The derivation of properties is set separately because each user has a different priority. There are two properties: a filtering property and a weighting property. The filtering property improves the recommen¬dation speed by removing an item if it is not purchased by the user or when it is not a condition, and the weighting property is input into the learning model as a priority for each user and is used when extracting mutual satisfaction. The consumer’s weighting property may include the consumer’s preference infor¬mation and evaluation information about the product and the supplier; the supplier’s weighting property may include the customer’s suitability or intention to purchase the product.
In the case of the first model, which predicts consumer satisfaction with a supplier, the properties may include consumer information (personal information, location, purchase history, etc.) and item preference information (rating, etc.) as in the existing recommender system model. In this study, the supplier’s information is added to these properties. In the second model for predicting supplier satisfaction with consumers, since items from the supplier’s perspective are already determined, only the information about consumers and suppliers is obtained. For the collected data, the numeric type is expressed as a value between 0 and 1 using min-max scaling for efficient learning, and the categorical type is converted using label encoding.
4.2 Prediction of User-Specific Satisfaction
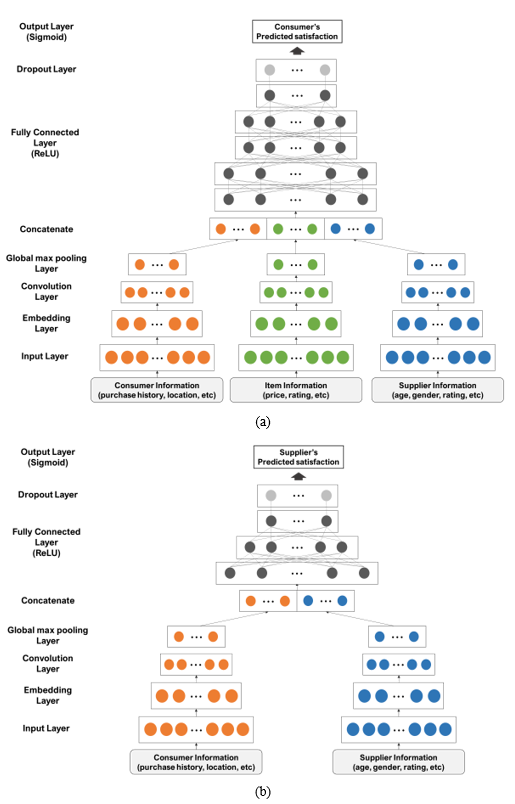
To predict the satisfaction level for each user, we constructed the consumer satisfaction prediction model (CM) and the supplier satisfaction prediction model (SM), both of which proceed with hybrid learning based on the CNN and DNN. This process extracts features from data input using the CNN, and then user satisfaction is predicted using the DNN.
Before predicting satisfaction using a model, information in the input layer is input in relation to an item to which a user-specific filtering property is applied. In the case of the CM, the item information and the supplier information related to the item are obtained for items that satisfy the condition that the consumer wants to fulfill by making a purchase. In the case of the SM, based on the consumer satisfaction prediction result, information regarding the top consumer is produced. This process can reduce unneces¬sary calculations.
The input data is transferred to the embedding layer. Since categorical variables are high-dimensional, mapping to low-dimensional space is necessary. In particular, since information about items includes rating and categorical variables regarding various aspects, embedding is performed because the data is larger than that used for other models. Next, the primary feature map is output by a convolution operation on metadata such as the consumer preference information, item information, and host information. Then, Global max pooling is used to translate to the lower dimension. After that, all embedding vectors are concatenated, and the weight of each node is corrected using a fully connected layer that predicts satisfaction. At this time, the rectified linear unit (ReLU) activation function is used for every layer of the hidden layer up to this point. The overfitting problem is solved using the dropout layer, which is located before the output layer, and the output layer derives the expected satisfaction using a sigmoid activation function that outputs a value between 0 and 1 that predicts satisfaction. The CM and SM models are similar, but because the input data are different, the number of hidden layers in both was adjusted as shown in Fig. 5(a) and 5(b).
4.3 Mutual Satisfaction Derivation
Mutual satisfaction is the satisfaction of both the consumer and the supplier. The key here is to consider the differences between the two users. Regarding mutual satisfaction, higher user satisfaction indicates better matching, but if the satisfaction of either user is low, the matching is not suitable. For example, as shown in Fig. 6, mutual satisfaction can be viewed by comparing three situations. In these three situations, the satisfaction of both the consumer and the supplier is equal to 8 on average. In the case of Fig. 6(a), the consumer is more satisfied than the supplier. In the case of Fig. 6(b), the supplier is more satisfied than the consumer. In the case of Fig. 6(c), the average of the consumer and the supplier is equal to 8. First, a smaller difference between the satisfaction of the consumer and the supplier indicates better satisfaction of the consumer and the supplier. Therefore, cases (a), (b), and (c), (c) should have the highest mutual satisfaction result. Next, when comparing (a) and (c), the satisfaction difference is the same. This equality does not mean that mutual satisfaction is the same because, as mentioned in Section 3.1, suppliers have fewer opportunities to make choices than consumers, and therefore, in this case, it is their first choice. For this reason, the consumer’s satisfaction is given slightly more priority.
Fig. 6.

Considering this factor, the mutual satisfaction [TeX:] $$\left(M S_{a, b}\right)$$ is derived by comparing the magnitude of the satisfaction score of both “consumer a” and the satisfaction score of “supplier b,” as shown in Eqs. (1) and (2). Before this calculation, the DNN model extracts the value of “consumer a” from consumers’ satisfaction (CS) and the value of “supplier b” from suppliers’ satisfaction (SS). Mutual satisfaction is calculated by subtracting the variance from the sum of the two values and dividing by 2. This process reflects the difference between the two values using a variance that is the deviation from the mean. A greater difference between the two values indicates lower mutual satisfaction because one of the two users may be unsatisfied.
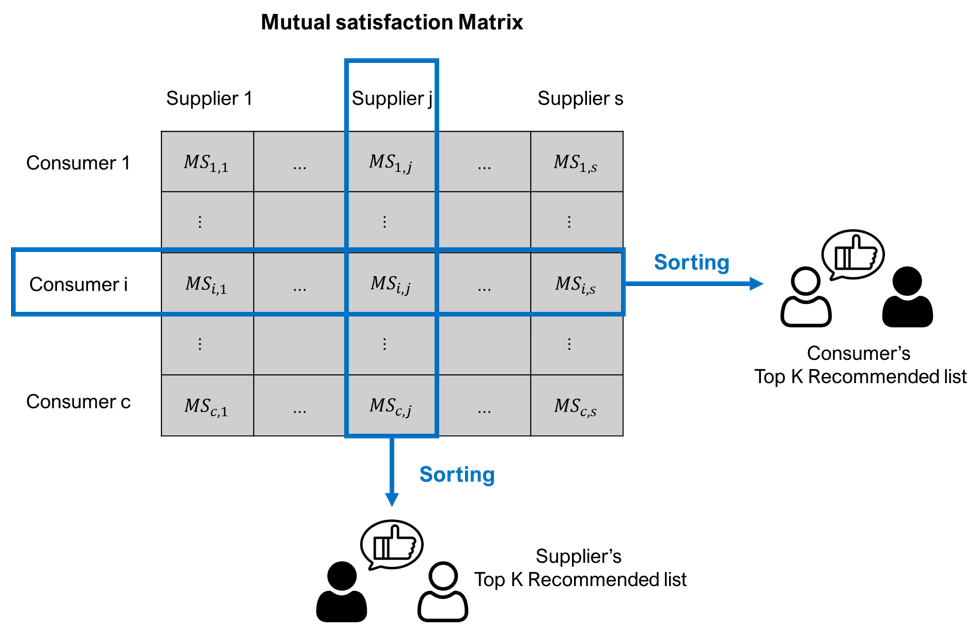
Finally, the mutual satisfaction is derived in the form of a consumer-supplier matrix as shown in Fig. 7. Based on this calculation, whenever the satisfaction of the consumer or supplier is predicted, it is updated with the predicted value. The recommended list is sorted in the order of the highest score for the user and generated by providing the appropriate number K of the supplier and the consumer.
(1)
[TeX:] $$M S_{a, b}=\frac{\left(C S_{a}+S S_{b}\right)-\frac{1}{2} \sqrt{\left(\frac{C S_{a}-S S_{b}}{2}\right)^{2}}}{2}\left(C S_{a}-S S_{b} \geq 0\right)$$
5. Experiment
5.1 Experimental Environment
The experiment was implemented using Python-based TensorFlow and Keras; Table 1 shows the experimental environment presented in this paper.
Table 1.
| Type | Value |
|---|---|
| CPU | Intel Core i7-8700K |
| GPU | GeForce GTX 1080 |
| RAM | 32 GB |
| Python | 3.6 |
| TensorFlow | 1.13.1 |
| Keras | 2.2.4 |
5.2 Dataset
To apply the matching service model proposed in this paper, we collected Airbnb data in New York from July 2019 to January 2020 from InsideAirbnb. It was judged whether or not to use accommodation based on a review written by the user, and only users who used Airbnb over four times were filtered. As a result, the experiment was conducted with 67,045 reviews as shown in Table 2.
Table 2.
| Details | Value |
|---|---|
| Period | July 2019 to January 2020 |
| Area | New York |
| Number of rooms | 17,978 |
| Number of hosts | 14,182 |
| Number of guests | 11,732 |
| Number of reviews | 67,045 |
5.3 User-Specific Property Settings
The filtering and weighting property set to derive mutual satisfaction are listed in Table 3. The filtering properties are for Airbnb accommodation information and are set as typical room type and region. In addition, the consumer recommended list, which is the result from the CM, is delivered and set as a filtering property in the SM.
Table 3.
| Property | Model | Data type | Element |
|---|---|---|---|
| Filtering | All | Item | Room type, Region |
| SM | Consumer | The consumer recommended list | |
| Weighting | CM | Consumer | Location, Preferred price |
| Item | Location, Price, Room type, Number of beds, Rating | ||
| Supplier | Location, Super host or not, Identity verified or not | ||
| SM | Consumer | The probability of writing a review, Location | |
| Supplier | Consumer location |
The weighting properties are separate in the CM and SM. In the CM, since the consumer information cannot include data such as gender or age for information protection, it was set to location and preferred price. Item information was set by location, price, room type, number of beds, and rating. The supplier information was set to the location of accommodation, super host or not, and identity verified or not. In the SM, since a supplier desires many reviews on his page, the weighting property sets the probability of writing a review and location among consumer information. At this time, the probability of writing a review is calculated by taking the average of the consumer’s review history. Additionally, among the weighting properties, the supplier’s information is set to the location.
5.4 Experimental Results
The experiment compared the UTU-MS proposed in this paper with the matrix factorization (MF) model, which is based on support value decomposition (SVD) and is frequently used in existing recom¬ recom¬mendation systems. To confirm the mutual recommendation performance, the experiment was conducted using four different configurations:
C1: only the CM model of the UTU-MS,
C2: UTU-MS,
C3: the MF model for unidirectional recommendation, and
C4: the MF model for mutual recommendation.
The model’s input data are properties specified in Section 5.3. Since Airbnb data does not provide information about ratings given by the guest, this information was obtained by setting the output data (i.e., on whether or not the actual guest selected the accommodation). For model training, the training data comprised 70% and the test data 30%. In addition, the model’s learning rate was 0.001, and 100 learning epochs were conducted. The performance evaluation involved calculating the precision and recall based on Table 4, thereby calculating the F-measure value. Precision is the percentage at which the consumer stays at the predicted hosts’ accommodation. Recall is the percentage of how many consumers were recommended specific accommodation that they then visited, which is calculated using Eqs. (3)–(5).
(5)
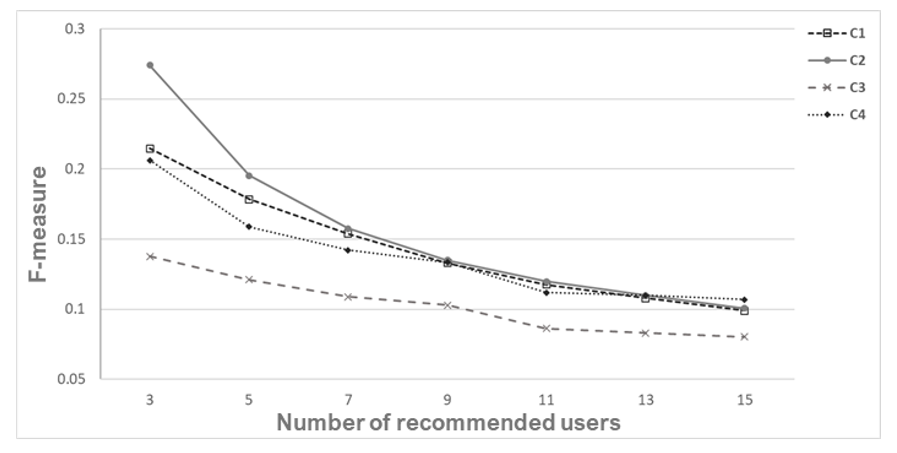
[TeX:] $$F-\text { measure }=\frac{2 \times \text { Precision } \times \text { Recall }}{\text { Precision }+\text { Recall }}$$Table 5 shows the results of evaluating the experimental performance of the proposed model. It is the average of the results of the experiments in terms of the number of recommended users for precision, recall and F-measure. Fig. 8 shows the F-measure of each model for the number of recommended users. It was confirmed that the methods C2 and C4, which carried out mutual satisfaction predictions, were slightly more dominant. In other words, it was shown that the F-measure value improved when using the recommendation model that calculates mutual satisfaction. In addition, when comparing the performance evaluation of C2 and C4, it was confirmed that the performance of C2 is approximately 13% higher. Through this experiment, it can be confirmed that the recommendation based on the prediction of user mutual satisfaction is meaningful, and the suitability of the UTU-MS model proposed in this paper was confirmed.
6. Conclusion
In this paper, a UTU-MS for use in a business platform based on a shared economy was proposed; in this context, the users are both consumers and suppliers. This classification suggests matching of the consumer to the supplier, unlike user–item recommendations in existing recommendation services. To this end, the priorities of consumers and suppliers were identified, and filtering and weighting properties were derived. Using the CNN-DNN-based learning model, satisfaction predictions from the consumer’s and supplier’s perspectives were synthesized, and mutual satisfaction was derived to make recommen¬dations. We conducted experiments using Airbnb data and confirmed better performance than the user–item recommendation method.
The proposed model can be said to be an optimized model for the sharing economy and is meaningful in that it is a recommendation that reflects the priorities of each user. However, since the prediction is performed using two models, it has a limitation in terms of learning speed. In future studies, we intend to study ways to improve the speed and increase the accuracy of recommendations to apply it to various sharing-based platforms.
Biography
Jinah Kim
https://orcid.org/0000-0002-3745-5522
She received B.S. and M.S. degrees from the School of Computer Science and Engineering at Hoseo University, Korea. She is currently pursuing a Ph.D. degree at the Department of Computer Science and Engineering, Hoseo University. Her research interests include smart services, deep learning, and big data processing and analysis.
Biography
Nammee Moon
https://orcid.org/0000-0003-2229-4217
She received B.S., M.S., and Ph.D. degrees from the School of Computer Science and Engineering at Ewha Womans University in 1985, 1987, and 1998, respectively. She served as an assistant professor at Ewha Womans University from 1999 to 2003, then as a professor of digital media at the Graduate School of Seoul Venture Information, from 2003 to 2008. Since 2008, she has been a professor of Computer Science and Engineering at Hoseo University. Her current research interests include social learning, HCI and user-centric data, deep learning, and big data processing and analysis.
References
- 1 H. Lee, W. Lee, "A study on the design and implementation of the learned life sports team recommendation service system based on user feedback information," Journal of Korea Multimedia Society, vol. 21, no. 2, pp. 242-249, 2018.custom:[[[-]]]
- 2 C. Yin, S. Ding, J. Wang, "Mobile marketing recommendation method based on user location feedback," Human-centric Computing and Information Sciences, vol. 9, no. 14, 2019.doi:[[[10.1186/s13673-019-0177-6]]]
- 3 H. Song, N. Moon, "Eye-tracking and social behavior preference-based recommendation system," The Journal of Supercomputing, vol. 75, no. 4, pp. 1990-2006, 2019.custom:[[[-]]]
- 4 H. T. Cheng, L. Koc, J. Harmsen, T. Shaked, T. Chandra, H. Aradhye, et al., "Wide & deep learning for recommender systems," in Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, 2016;pp. 7-10. custom:[[[-]]]
- 5 H. Wang, N. Wang, D. Y. Yeung, "Collaborative deep learning for recommender systems," in Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 2015;pp. 1235-1244. custom:[[[-]]]
- 6 K. So, Y. Lee, K. Moon, K. Ko, "Design of bi-directional recommend calligraphy contents open-market platform," Journal of Korea Multimedia Society, vol. 18, no. 12, pp. 1586-1593, 2015.custom:[[[-]]]
- 7 M. Fu, H. Qu, Z. Yi, L. Lu, Y. Liu, "A novel deep learning-based collaborative filtering model for recommendation system," IEEE Transactions on Cybernetics, vol. 49, no. 3, pp. 1084-1096, 2018.custom:[[[-]]]
- 8 F. Liu, R. Tang, X. Li, W. Zhang, Y . Ye, H. Chen, H. Guo, and Y . Zhang, 2018 (Online). Available:, https://arxiv.org/abs/1810.12027
- 9 L. Zheng, V. Noroozi, P. S. Y u, "Joint deep modeling of users and items using reviews for recommendation," in Proceedings of the 10th ACM International Conference on Web Search and Data Mining, Cambridge, UK, 2017;pp. 425-434. custom:[[[-]]]
- 10 P. Vilakone, D. S. Park, K. Xinchang, F. Hao, "An efficient movie recommendation algorithm based on improved k-clique," Human-centric Computing and Information Sciences, vol. 8, no. 38, 2018.doi:[[[10.1186/s13673-018-0161-6]]]
- 11 K. Xinchang, P. Vilakone, D. S. Park, "Movie recommendation algorithm using social network analysis to alleviate cold-start problem," Journal of Information Processing Systems, vol. 15, no. 3, pp. 616-631, 2019.custom:[[[-]]]
- 12 S. C. Oh, M. Choi, "A simple and effective combination of user-based and item-based recommendation methods," Journal of Information Processing Systems, vol. 15, no. 1, pp. 127-136, 2019.custom:[[[-]]]
- 13 O. Lee, E. S. You, "Predictive clustering-based collaborative filtering technique for performance-stability of recommendation system," Journal of Intelligence and Information Systems, vol. 21, no. 1, pp. 119-142, 2015.custom:[[[-]]]
- 14 Y. Y un, D. Hooshyar, J. Jo, H. Lim, "Developing a hybrid collaborative filtering recommendation system with opinion mining on purchase review," Journal of Information Science, vol. 44, no. 3, pp. 331-344, 2018.doi:[[[10.1177/0165551517692955]]]
- 15 F. Y u, N. Che, Z. Li, K. Li, S. Jiang, in Advances in Knowledge Discovery and Data Mining, Switzerland: Springer, Cham, pp. 91-105, 2017.custom:[[[-]]]
- 16 J. Wei, J. He, K. Chen, Y. Zhou, Z. Tang, "Collaborative filtering and deep learning based recom-mendation system for cold start items," Expert Systems with Applications, vol. 69, pp. 29-39, 2017.custom:[[[-]]]
- 17 J. Kim, N. Moon, "Rating and comments mining using TF-IDF and SO-PMI for improved priority ratings," KSII Transactions on Internet and Information Systems, vol. 13, no. 11, pp. 5321-5334, 2019.custom:[[[-]]]
- 18 S. Zhang, L. Yao, A. Sun, Y. Tay, "Deep learning based recommender system: a survey and new perspectives," ACM Computing Surveys, vol. 52, no. 1, pp. 1-38, 2019.custom:[[[-]]]
- 19 P. Xia, B. Liu, Y. Sun, C. Chen, "Reciprocal recommendation system for online dating," in Proceedings of 2015 IEEE/ACM International Conference on Advances Social Networks Analysis and Mining (ASONAM), Paris, France, 2015;pp. 234-241. custom:[[[-]]]
- 20 T. R. Kacchi, A. V. Deorankar, "Friend recommendation system based on lifestyles of users," in Proceedings of 2016 2nd International Conference on Advances Electrical, Electronics, Information, Communication and Bio-Informatics (AEEICB), Chennai, India, 2016;pp. 682-685. custom:[[[-]]]
- 21 C. Narasimhan, P. Papatla, B. Jiang, P. K. Kopalle, P. R. Messinger, S. Moorthy, et al., "Sharing economy: review of current research and future directions," Customer Needs and Solutions, vol. 5, no. 1, pp. 93-106, 2018.custom:[[[-]]]
- 22 H. Abdollahpouri, G. Adomavicius, R. Burke, I. Guy, D. Jannach, T. Kamishima, J. Krasnodebski, and L. Pizzato, 2019 (Online). Available:, https://arxiv.org/abs/1905.01986
- 23 R. Burke and H. Abdollahpouri, 2017 (Online). Available:, https://arxiv.org/abs/1905.01986
- 24 E. C. Malthouse, K. A. V akeel, Y. K. Hessary, R. Burke, M. Fuduric, "A multistakeholder recommender systems algorithm for allocating sponsored recommendations," in Proceedings of the Workshop on Recom-mendation Multi-stakeholder Environments co-located with the 13th ACM Conference on Recommender Systems (RecSys), Copenhagen, Denmark, 2019;custom:[[[-]]]
- 25 O. Surer, R. Burke, E. C. Malthouse, "Multistakeholder recommendation with provider constraints," in Proceedings of the 12th ACM Conference on Recommender Systems, V ancouver, Canada, 2018;pp. 54-62. custom:[[[-]]]