Mookyung Kwak , Ji Su Park and Jin Gon Shon*
Identifying Critical Factors for Successful Games by Applying Topic Modeling
Abstract: Games are widely used in many fields, but not all games are successful. Then what makes games successful? The question gave us the motivation of this paper, which is to identify critical factors for successful games with topic modeling technique. It is supposed that game reviews written by experts sit on abundant insights and topics of how games succeed. To excavate these insights and topics, latent Dirichlet allocation, a topic modeling analysis technique, was used. This statistical approach provided words that implicate topics behind them. Fifty topics were inferred based on these words, and these topics were categorized by stimulation-response-desire-goal (SRDG) model, which makes a streamlined flow of how players engage in video games. This approach can provide game designers with critical factors for successful games. Furthermore, from this research result, we are going to develop a model for immersive game experiences to explain why some games are more addictive than others and how successful gamification works.
Keywords: Critical Factors , SRDG Model , Successful Game , Topic Modeling
1. Introduction
Video game has a short history. Nevertheless, it became a worldwide phenomenon, the global games market is estimated to generate revenues of $159.3 billion in 2020 according to Global Games Market Report [1]. Many researchers are already working on solving the puzzles which make players to become so addicted to the games. However, the mystery does not reveal itself easily. Game designers are still struggling to find out useful principles that work in their pieces of art.
What makes this more complicated is the changes in trends. We have been through big waves in video game technologies in a relatively short period of time. It can be also expected that augmented reality and virtual reality will change a lot in video game industry. Sometimes these new technologies' impact is so strong that the horizon of industry would be distorted permanently. Therefore, we need a research methodology which can embrace all these aspects. In this context, topic modeling analysis came up as it can help to organize and offer insights from large collections of unstructured text bodies [2]. As the name itself denotes, this technique demonstrated its usefulness in extracting meaningful topics from large text dataset.
In this study, we apply latent Dirichlet allocation (LDA) as topic modeling analysis technique. LDA was first introduced in 2003 from [3], then became de facto standard in information retrieval field. Many researches already showed that performance of LDA is outstanding in classifying documents [4-8].
To become candidate for the dataset to be fed to topic modeling, following standards should be met: firstly, the data should be big enough to provide various topics. Secondly, the text should be rich with insights and information of what make games successful. To satisfy these criteria, we crawled game reviews from Metacritic website [9]. The game reviews were written by game magazine reporters who can be considered as experts in gaming field and can be supposed to have abundant information about how games succeed. After LDA was performed on the pre-processed crawled reviews, we got 50 sets of topics supporting words. From these supporting words, we inferred descriptions for topics which explain well what the topics would mean.
In the basis of the descriptions above, we pulled out a model which describes how video game players get in the cycle of immersion and the elements which serve as critical factors for successful games. We propose this research would contribute in two ways. Firstly, the model would be a firm step to explain how game's addictiveness works. Not only game designers but also educators who need to design more appealing curricula would benefit from this work. Secondly, the methodology used in this study would be a useful toolbox for researchers who are trying to design robust and reproducible models.
2. Background
2.1 Models for Immersive Game
Researchers introduced various tools from psychology and educational theories to make models explaining why games are so immersive. These approaches help us to understand dynamics between games and players, and also provide base camp for our study. Following researches suggest good points describing what are essential for good games.
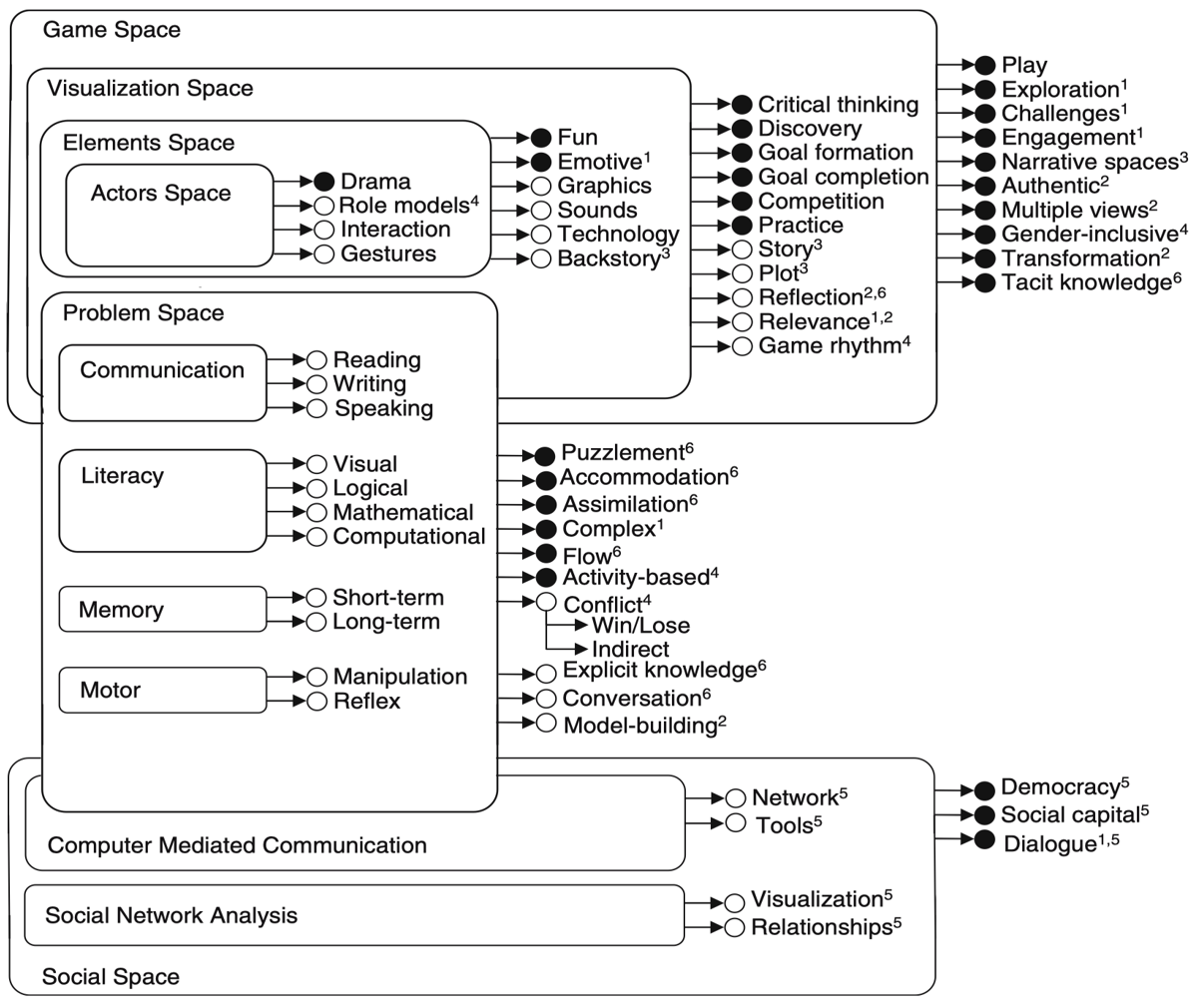
2.1.1 Game object model
"Game object model" which introduced educational theory to game design was introduced in [10]. Constructivist educational theory contributed to the model by emphasizing the importance of building or constructing knowledge by learners themselves. As the name itself denotes, this model shows that we can divide video games into several entities and attributes which represent the abstract and concrete aspects of objects in objective oriented programming theory.
As you can see in Fig. 1, this model consists of various objects which are represented by boxes. And the objects have properties with open or closed circles. These properties are called interfaces in which the concept was borrowed from objective oriented programming as described above. What open circle represents is concrete interface, whereas closed is for abstract one. As if concrete means more specific implementation than that of abstract interface in objective programming concept, these concrete interfaces in the model work as materialization of the objects. Moreover, the objects can inherit from each other as in objective oriented programming. For example, Visualization Space inherit from Game Space, then the inherited object has more of concrete interfaces than its parent does.
This model provides a good basis for designing and evaluating educational games. A simple check list from this model could be all the necessary criteria for designing and evaluating educational game [10]. This model is acknowledged as providing a mechanism to review computer games from an educational perspective. In this study, this model inspired the concept that concrete topics materialize abstract ones in the form of categories and sub-categories.
Table 1.
| Feature type | Sub-features | Example |
|---|---|---|
| Social Features | Social utility features Social formation/institutional features Leader board features Support network features | In-game voice and text chat Guilds/clans in MMORPGs "Hall of fame" high score list Internet forums, strategy guides |
| Manipulation and control features | User input features Save features Player management features Non-controllable features | "Combos", "hot keys" Checkpoints, "quick-save" Managing multiple resources Scripted events, loading screens |
| Narrative and identity features | Avatar creation features Storytelling device features Theme and genre features | Choice of sex, race, attributes Cut-scenes, mission briefing "Role-playing", "shooting" |
| Reward and punishment features | General reward type features Punishment features Meta-game reward features Intermittent reward features Negative reward features Near miss features Event frequency features Event duration features Payout interval features | Experience points, bonuses Losing a life, restarting a level Xbox 360 achievement points Increasing difficulty of levels Gaining health, repairing items Difficult "boss" at end of level Unlimited replayability of game MMORPGs have no endpoint Rewarded instantly for playing |
| Presentation features | Graphics and sound features Franchise features Explicit content features In-game advertising features | Realistic graphics, fast music Trademarked names, e.g., Mario Violence, drug uses, nudity Real-life brands, sponsors logos |
Adapted from [11] with permission of Springer Nature.
2.1.2 Five-feature model of video game structural characteristics
In [11], the authors focused on the similarities between excessive video game playing behavior and abnormal gambling frequency. Video game is a comparatively new field than gambling in which a lot of literatures are trying to identify structural characteristics of extraordinary gambling frequency and expenditure. They proposed that classifying and organizing the psycho-structural elements of video games would help understand mechanism of game dynamics. In this attempt, five features are suggested which includes (1) social features, (2) manipulation and control features, (3) narrative and identity features, (4) reward and punishment features, and (5) presentation features.
In Table 1, you can see five main features and descriptive sub-features which specify what main features do. In addition, examples provide detailed application use cases that are useful for game designers. This approach benefits from the achievement of psychology and focused on what characteristics move players mind, that is emphasizing psychological aspects in game design. When developing the model in this study, this psychological aspect was considered as main factor which drives dynamics of the model.
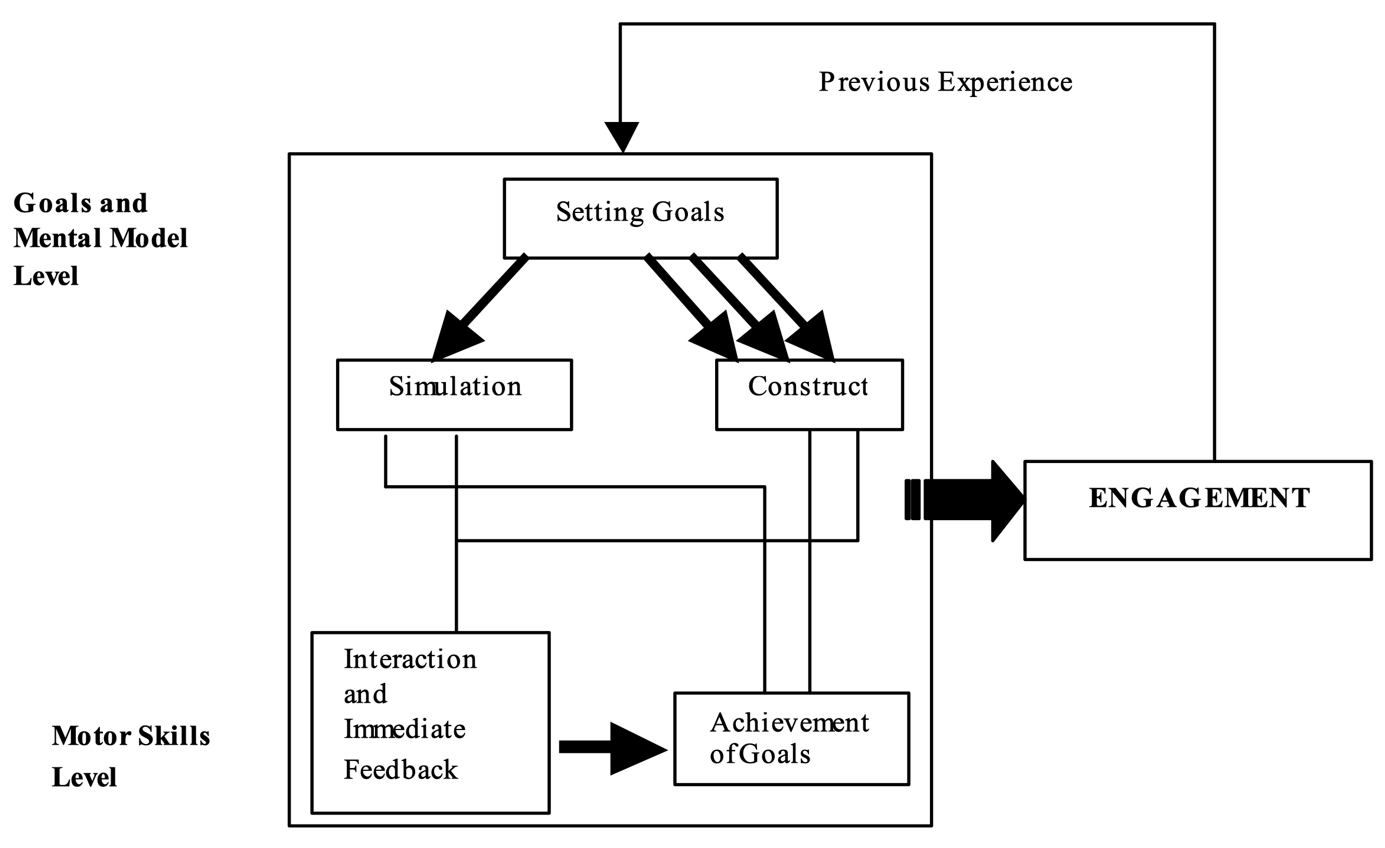
2.1.3 Engaging multimedia design model
Cyclic aspect of game user's mental model which makes users engaged in the educational games is emphasized in [12]. Interactions and immediate feedbacks pile up to become game user's experience, then this experience converts to goals. And by achieving these goals, users engage in the video game more and more. This cyclic flow is self-reinforcing, which explains why games are so addictive. All the five factors and the cyclic flows are schematized in Fig. 2. The insight that the momentum which was accumulated through the levels of the model can reinforce itself in cyclic manner affected our model thoroughly.
2.2 Applying Machine Learning to Building Model
Models provide a good basis to explain present state and to predict future. Naturally, scholars are trying to build their own model in the mental form or more concretely in research papers. This modeling process is inherently introverted, so that it would be simply not possible to verify the validness of modeling procedure. Even though this black-box process proves the greatness of human intelligence, researchers are often tempted to fabricate more objective, full of evidence, and reproducible process of making a model.
Dawn of statistics and machine learning shines the ambitious way to this new approach. The study of natural language processing started in the 1950s, and flourished in a recent decade in the forms of document classification, language translation, and speech recognition tasks. These applications achieved higher level when neural networks are introduced in the early 2010s. Nevertheless, statistical methods are establishing foundations in neural network approach, and are providing more interpretable manners.
Topic modeling analysis is one of the machine learning applications, which is first developed as a tool for information retrieval field. As Internet grows exponentially, the amount of written text we encounter also explodes, then the need to organize the documents with similar structures or topics into groups became desperately needed. Topic modeling is originally developed as a text-mining tool, but it is also used in genetic information, images and networks.
The mainstay of topic modeling analysis is extracting meaningful topics from unstructured text bodies. This means that the technique can handle massive data which cannot be handled by human researchers. It is the main reason why we use this technique in the study. It is expected that big data would harbor plenty of insights and topic modeling would organize them without any bias originated from human being.
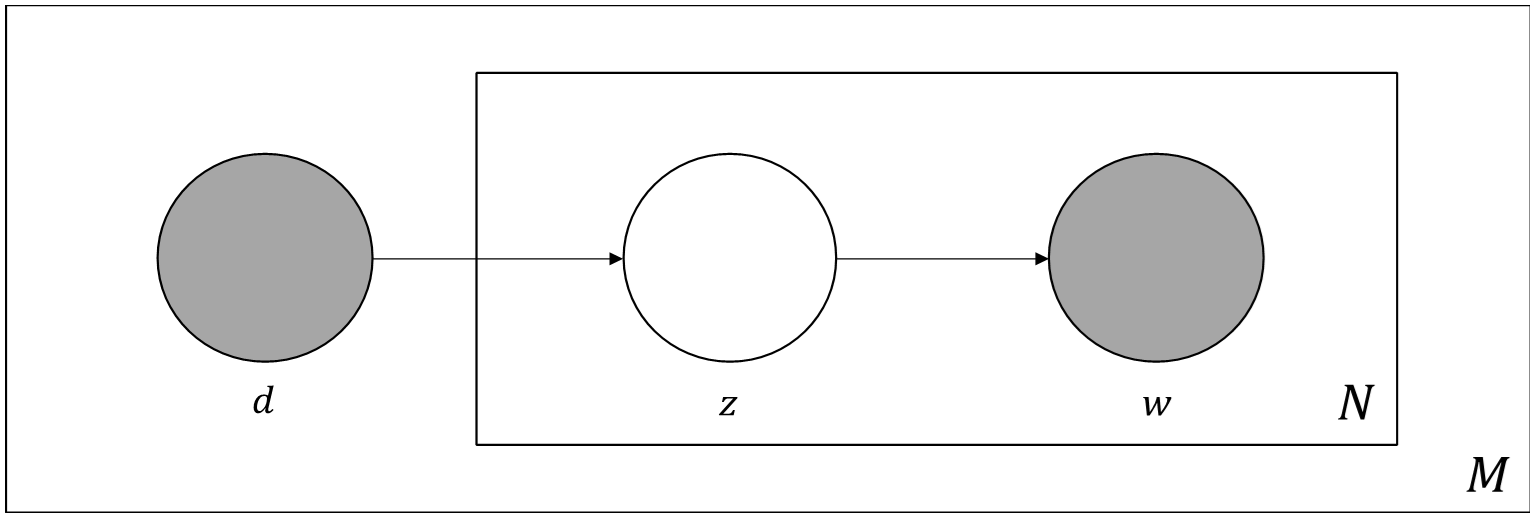
Latent semantic indexing (LSI) was a first runner in the area. LSI tried to enhance query results by using truncated singular value decomposition (SVD) which estimate the structure in word usage across documents [13]. In other words, the SVD derives the latent semantic structure model from term and document vectors, meanwhile the truncated SVD only captures most of the important underlying structure which means it removes the noise or variability in word usage [13]. This approach showed its usefulness especially in recognizing synonymy, by merging the dimensions that have similar meanings. Practically, this means that the terms having a common meaning are roughly mapped to the same direction in the latent space [14]. After successful debut of LSI, probabilistic latent semantic indexing (PLSI) introduced new approach which is called aspect model that is a latent variable model for co-occurrence data. This approach has a solid foundation in statistics compared to LSI which, allegedly, has its theoretical foundation as unsatisfactory and incomplete to a large extent [14]. In the following PLSI model, d represents documents and w is for words, given an unobserved topic z. Topic number is a hyperparameter which should be selected by researcher.
Fig. 3 shows graphical representation of above formula. In this figure, you can have general ideas about how topics work in the model. Documents exhibit multiple topics which is latent variable whereas d and w are observable variables. In addition, d and w are independent conditioned on the state of the associated latent variable which is z in this case, and N denotes for number of words in given documents while M is for number of documents. PLSI introduced statistical achievement to predicting distribution of documents, topics and words. This approach was not only a success itself but also became an inspiration to other researches.
LDA was induced in this context. It is also based on generative statistical model but being improved. PLSI treats the topic mixture weights as a large set of individual parameters which are explicitly linked to the training set whilst LDA treats them as a k-parameter hidden random variable that generalize to new documents easily and avoid overfitting issues [3].
To describe LDA model, plate notation in Fig. 4 can be used for more concise explanation. In the figure, is the parameter of the Dirichlet prior on the per-document topic distribution, and is the parameter of the Dirichlet prior on the per-topic distribution, while is the topic distribution for a given document and [TeX:] $$\varphi$$ is the word distribution for topic K. The outer plate denotes documents, and the inner represents the repeated word positions in a given document. Compared to PLSI, words which is represented by w are the only observable variables, while the others are latent.
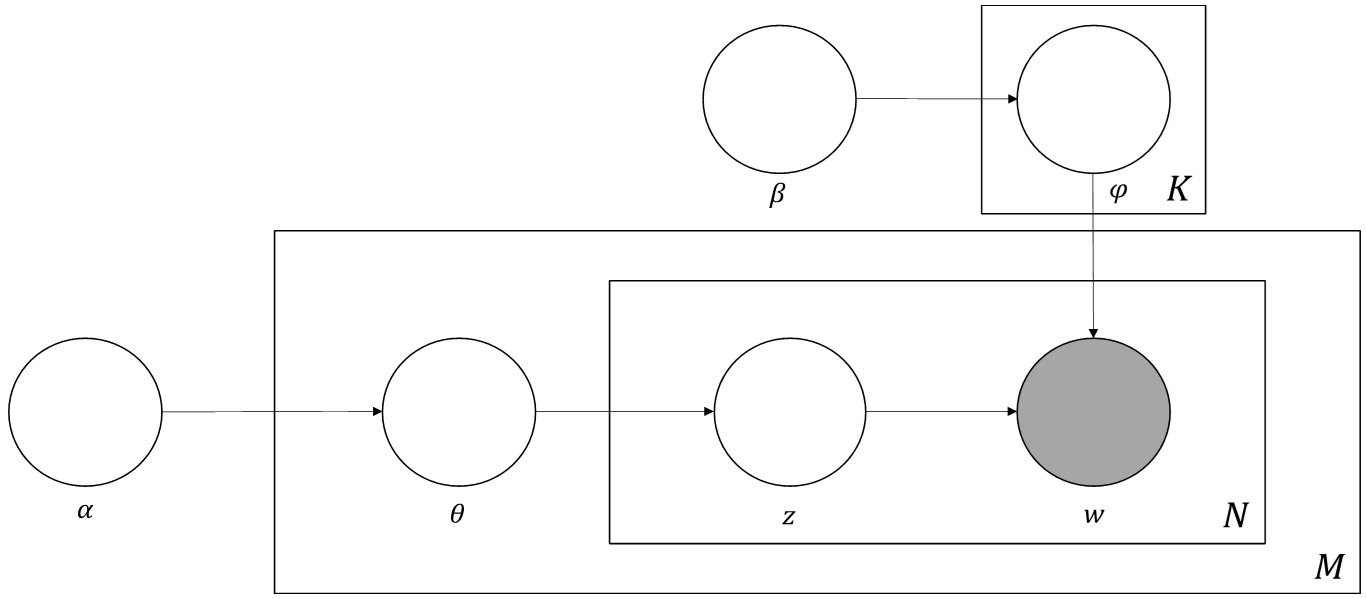
The origin of name LDA is that [TeX:] $$\varphi$$ is assumed to follow Dirichlet allocation. Elements of [TeX:] $$\varphi$$ are probability of words and the total of elements in each [TeX:] $$\varphi$$ is 1. To infer topics in a corpus, LDA suppose that words are generated from the combination of words distribution in topic ([TeX:] $$\varphi$$) and topic distribution in document ). In this assumption, the joint probability of [TeX:] $$\varphi$$ and is supposed to be maximized. To do this, sampling technique like Gibbs Sampling is used to approximate posterior probability.
In this model, the topics are latent, and words sit on the topics, so the results of modeling will only show a list of categorized words which need to be interpreted by researcher's own words and intuition. In this study, this is done in Section 4.3 in the title of inferring topics
3. Methodology
In brief, we had to make three important decisions in our study. Firstly, which data could be a good resource to be analyzed? To be analyzed by topic modeling technique, the data should be abundant in volume and should harbor abundant implications. The game reviews written by reporters should meet these criteria. In the game review website, there are many game reviews which are written by reporters and they can be crawled to be a standard form. Secondly, which topic modeling technique should be applied to the data? To answer this question, we studied topic modeling analysis in Section 2.2, and we concluded LDA is the most valid method to our problem. Thirdly, how can we infer topics from supporting words which are provided after LDA analysis? To handle this properly, we consulted on researches about game models in Section 2.1. Fundamentally, it depends largely on researcher's knowledge and experience, so we devoted to being rigorous in this procedure.
In Fig. 5, the three points above are depicted in more detail. First three processes (①-③) belong to obtaining data. Next four procedures (④-⑦) relate to applying topic modeling to the data. Final step (⑧) is about how we use produced results to build model.
The gathered data in ① should be pre-processed to be cleaned. Crawled data usually have duplicates or wrongly addressed contents. In step ③, a big corpus is made from the cleaned data, and it is vectorized in the form of non-negative matrix factorization (NMF) with term frequency-inverse document frequency (TF-IDF) features in step ④. This non-negativity helps the resulting matrices easier to be inspected. To decide the number of topics, perplexity test is executed in ⑤. With the topic number being decided in ⑤, LDA is applied to the matrix produced in ④. With topic supporting words which are produced in ⑦, we focused on inferring topics and building model along with previous knowledge in ⑧.
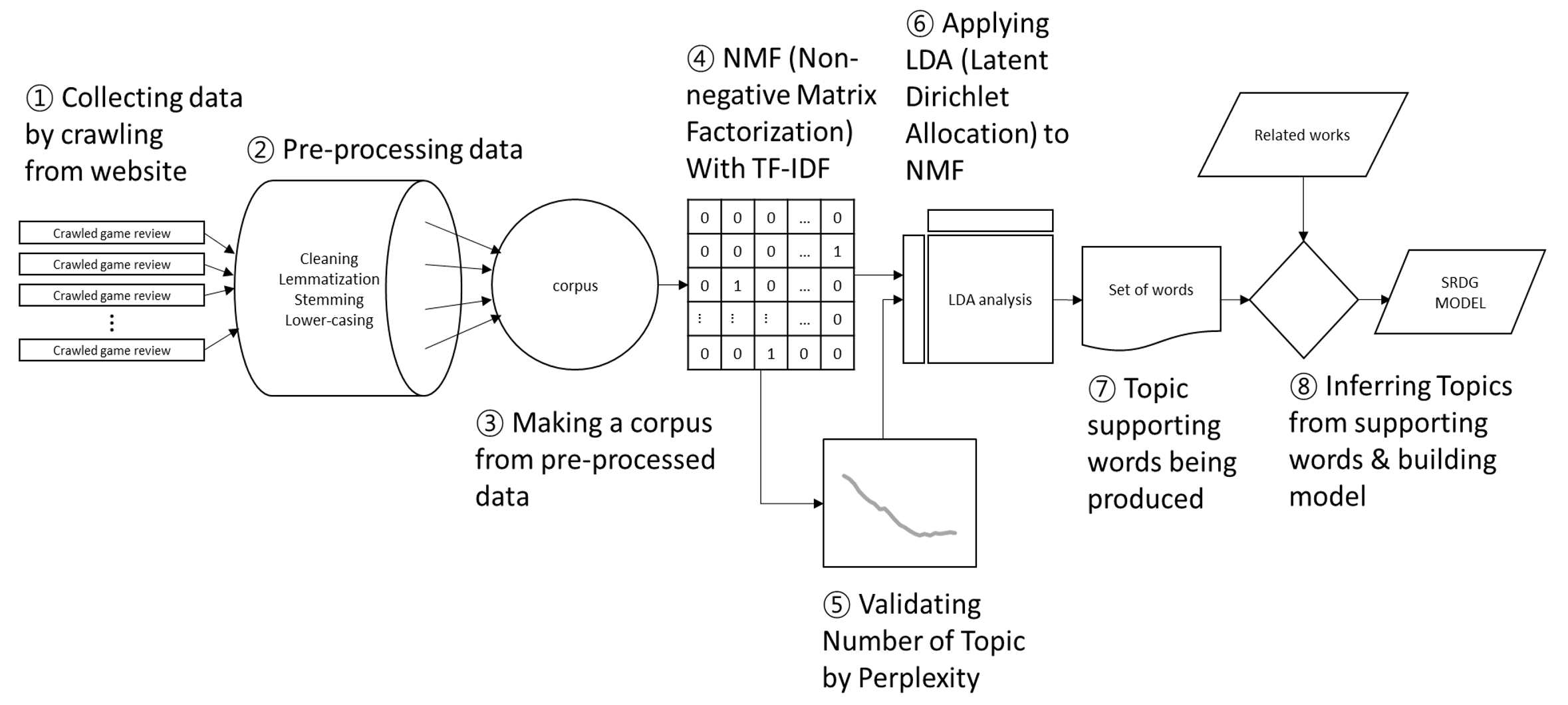
Using machine learning technique to identify topics for building model is a discerning point in our methodology. Therefore, the results of this study are reproducible, and it is also possible that we can get better results with more abundant and newer reviews.
4. Experiment
4.1 Collecting and Pre-processing Game Reviews
Game reviews are presumably full of helpful insights for successful games. However, the problem is where and how we collect them. We have chosen Metacritic game review website (https://www. metacritic.com/game) which is very famous in the field and continued for several decades. The reviews date between 1996 and 2019 are collected by website crawling technique. The crawled reviews added up to 8,465 and decreased to 7,745 reviews after cleaning up duplicates and dead links.
4.2 Applying LDA to Game Reviews
After review data being crawled from game review site, text pre-processing procedure is applied. In this process, all words are lowercased, and punctuations are removed, then lemmatization and stemming were applied. With pre-processed text data, one big corpus was made from which TF-IDF vectors extracted. During vectorization, stop words were removed from the corpus. The TF-IDF vectors have 1,000 features in which all the words are characterized including similarities and relations between words.
Number of topics is an arbitrary hyperparameter which should be decided by researcher. With help of perplexity, however, we concluded 50 is adequate topic number. LDA was applied to the corpus along with the parameter, then 50 sets of words are produced. The produced 50 sets of words are displayed in Table 2.
Table 2.
| enemi level use attack time like boss make power play | ball shot golf cours play hit power park hole swing |
|---|---|
| charact play array releas like make fighter version level adventur | st unit battl gy turn base war enemi map attack |
| wii version control ps array consol remot like play year | iphon mobil app screen tap io control touch avail zombi |
| anim fish pet hunt hunter dog creatur water like differ | level time adventur world item player way use make stage |
| charact battl rpg stori fantasi final quest dungeon world magic | ii fighter street vs edit arcad fight origin releas super |
| level play like time way race bit screen forc need | play like charact adventur enemi array differ way fun time |
| song music man danc rock band guitar play track note | idea mario play sega nintendo level charact head allow certain |
| new onlin build play citi time money start like free | ninja time enemi thing use like level charact iii good |
| origin seri new titl releas fan gameplay featur play year | player team play sport like year footbal make season mode |
| fight charact attack punch button combo mode special battl stori | legend shine link dungeon past histori best fantast old becom |
| tabl ninja pinbal iii machin ball real physic like hit | star space war episod forc planet univers zone movi destroy |
| dark girl dead zombi evil night blood room light hous | strang planet sega share time action note level rememb best |
| sim simul flight fli plane blank train upvot leav air | learn tool basic process use select verdict space articl make |
| mode play time control player level sound score challeng differ | land dream level boss come boy nintendo platform complet time |
| level street fighter ii make version mani special play boss | ninja like iii make attack jump master everi realli charact |
| rate help play replay valu ing overal fun great realli | thought whatev tv psp shadow close iii effect blow coupl |
| player play card match oppon board mode multiplay win singl | like time make thing play realli look way littl actual |
| hero warrior rise power iii forc psp stand death battl | adventur dark world level like use charact base releas make |
| level enemi shoot ship shooter weapon like alien gun screen | race car track drive speed racer vehicl like event time |
| fighter charact fight street ii version play graphic like arcad | stage level best time mario play world great super charact |
| parti famili member activ road age anoth time money like | puzzl block tile level match solv number screen color piec |
| mission enemi weapon player control time action use multiplay combat | sonic sega shadow ring crazi stage platform level drive adventur |
| way time stage array offer hit everi level pictur work | word site ed contain like think parti time al ing |
| movi platform jump level control film kid camera charact minigam | video current like moment power card fit scene super produc |
| chapter help past dungeon time team link ing rate best | ds mario nintendo mini super screen stylus touch titl play |
4.3 Inferring Topics
With 50 sets of 10 supporting words described in Table 2, researchers are required to infer topics behind those words. This process depends largely on researcher's intuition and prior experiences. Thus, for the sake of objectivity, we consulted on the visualization tool which shows relations between topics and words dynamically.
In [15], the authors wanted to answer following basic questions which are raised frequently in LDA analysis: What is the meaning of each topic? How prevalent is each topic? How do the topics relate to each other? And they supposed interactive and visualizing tool would be the answer.
Figs. 7 and 8 show visualized results with pyLDAvis library which help to interpret the topics. This library consists of two panes. The left one shows all the topics in the form of blue circles. The size and distribution mean the proportion and the distances between topics. We checked whether the topics are well distributed or not by inspecting the distribution among the circles and the sizes of circles compared to the others.
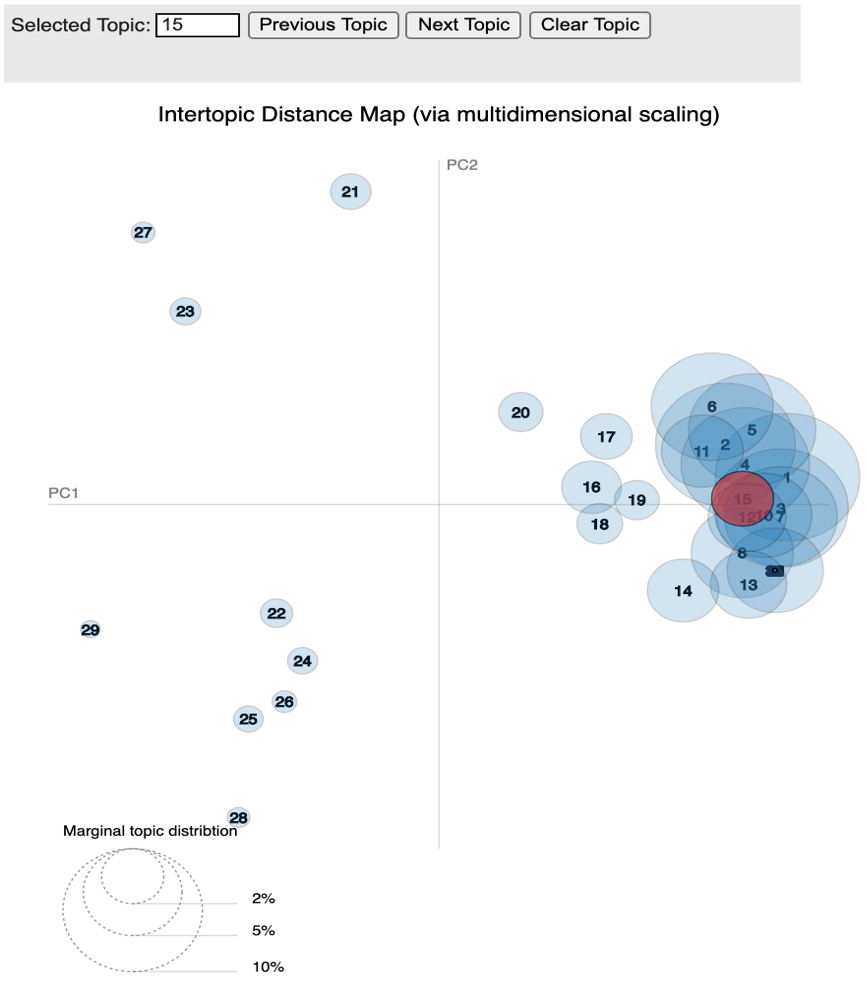
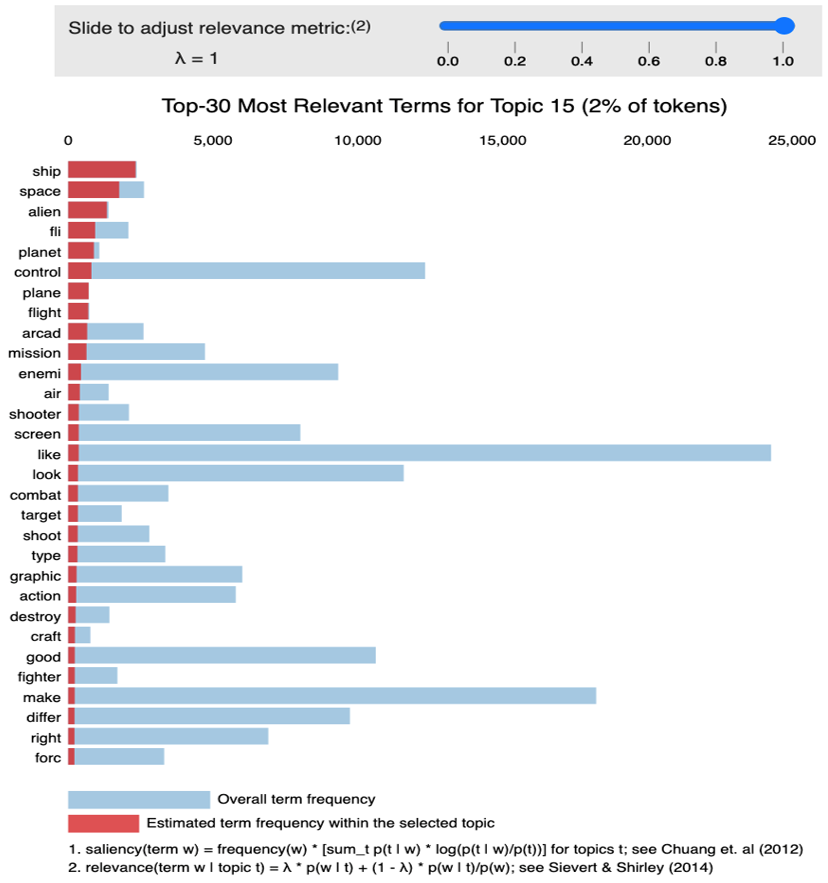
Suppose that we selected an arbitrary topic in this case the number 15 that is red circle in Fig. 7. As you can verify in Fig. 8, top supporting words are ship, space, alien, fly, planet. You can get the image of what these words are implying. In this process, we inspected every topic to infer meaning properly.
The final 50 inferred topics are shown in Table 3. These topics are inferred from supporting words by researcher. These topics themselves provide precious implications about what aspects or features impact players' motivation. So, we can use them as strategies when we make games or adapt to gamifications. As it were, we can look through all these items and get ideas applicable when we design games.
Table 3.
| stacking up level | being a hero | medieval times fantasy |
|---|---|---|
| Adventure | outrageous power | space fantasy |
| sense of physical control | flash visual stimulation | odd experience |
| hunting prey | being social through party game | learning process |
| storytelling | achieving mission | creative play |
| time attack | giving the entire picture | fast reflection |
| feel the rhythm of music | easy but continuous challenge | my own little world |
| build up | imitating sport play | explore unrealistic world |
| fan of franchise | imitating sport play | explore unrealistic world |
| belching violence | planning strategy | sensation of speed |
| eye-hand coordination | frantic stimulus-response cycle | becoming a super-power |
| crush everything except me | getting richer | solving puzzle |
| simulating reality elaborately | defeat others | overcome invincible adversity |
| ear-hand coordination | in the shoes of a character | bragging intelligence |
| special skills | fan of character | spectacular scenes |
| watch others to play | using items creatively | old franchise, new game |
| improving skills | planning everything | - |
5. Results
5.1 Stimulation-Response-Desire-Goal (SRDG) Model
If you group and sort these resources out, you will get more implications. Inferred topics with categories and sub-categories are sorted out in Table 4. This grouping is based on neurophysiological evidences that primates inherently use two different strategies to process information efficiently. Corbetta and Shulman [16] proposed that attentional functions are dependent on two different types of systems, goal-directed (top-down) and stimulus-driven (bottom-up), which are from totally different part of brain areas.
In the sense, we developed the SRDG model. Game designers want to catch players' attention by using various stimuli like flashing graphics or familiar characters, but proper response is also required to maintain the attention. This can be called bottom-up approach. However, gamers usually expect more than just sensory stimulus, thus game designers should provide various goals which can direct gamers to focus on specific stimulus and keep the attention. This can be regarded as top-down approach. These approaches can be adapted to the mutual connections among stimulus, response, desire, and goal, respectively.
In the model, four major categories are introduced including stimulation, response, desire, and goal. The leading categories are considered as bottoms to the trailing ones. And sub-categories are also provided to bridge categories and the topics. These sub-categories also can be used to describe what categories do in detail.
Table 4.
| Category | Sub-category | Topics |
|---|---|---|
| Stimulation | Low-level stimulus | flash visual stimulation |
| sensation of speed | ||
| High-level stimulus | fan of franchise | |
| storytelling | ||
| giving the entire picture | ||
| imitating sport play | ||
| fan of character | ||
| medieval times fantasy | ||
| space fantasy | ||
| old franchise, new game | ||
| Response | Impromptu response | time attack |
| feel the rhythm of music | ||
| eye-hand coordination | ||
| ear-hand coordination | ||
| sense of physical control | ||
| frantic stimulus-response cycle | ||
| fast reflection | ||
| Strategic response | build up | |
| planning strategy | ||
| using items creatively | ||
| planning everything | ||
| creative play | ||
| Desire | Desire of defeating | belching violence |
| crush everything except me | ||
| watch others to play | ||
| special skills | ||
| outrageous power | ||
| defeat others | ||
| Desire of achieving | hunting prey | |
| improving skills | ||
| stacking up level | ||
| achieving mission | ||
| easy but continuous challenge | ||
| getting richer | ||
| solving puzzle | ||
| my own little world | ||
| Desire of learning | simulating reality elaborately | |
| learning process | ||
| experience real world | ||
| Desire of being social | being social through party game | |
| adventure in teamwork | ||
| Desire of new world | adventure | |
| odd experience | ||
| explore unrealistic world | ||
| spectacular scenes | ||
| Desire of being others | being a hero | |
| in the shoes of a character | ||
| becoming a super-hero | ||
| Goal | Internal growth | overcome invincible adversity |
| External showing off | bragging intelligence |
To be more specific, descriptions on how these main categories and sub-categories are working together are provided in the following: there are games which focus on sensation of speed or flashing graphics which belong to low-level stimulus, while motivation of story or character excite players in a higher level. User's response to these stimuli can be categorized into impromptu or strategic ones. A lot of rhythm games require user's impromptu response to flash stimulus, while for instance defense games require user's creativity and planning. Stimulus response pattern invoke players' desire. These desires have lots of forms like desire of defeating others or achieving missions or learning how to pilot a plane or being social with others in party game. Experience new world or being others can be another example. These specific forms of desires sometimes invoke goals. The goals can be provided by game designers, but the term goal defined here should be set by players themselves.
5.2 Applications of the Model
All these stimuli, response, desire and goal make a streamlined flow of how players engage in video games. We can call this SRDG Model to abbreviate the four stages. And these four stages also implicate that they are steps to take effect of being immersed in the game.
These steps can be used as guidelines to depend on. Game designers use various stimuli to catch user's attention, but proper response is also needed to keep the attention. Anyhow, gamers usually expect more than just sensory stimulus, thus game designers also provide various objects of desires or goals which can direct users to be immersed in the game for a long time. And the sub-categories and topics can be used as specific strategies to implement these plans and actions. When game designers are working on game dynamics, they can evaluate whether their game has sufficient features from both bottom-up and top-down point of views. If this examination leads to lack of features, sub-categories and topics would act as a treasure box for more detailed and practical strategies.
This model also can be partially applied to various fields. For instance, when we develop educational courses, it is also important to fill the gaps between students' attention. In that case, "desire of being others" or "high-level stimulus" could imply a lot of possible means to raise students' attention. In addition, the four stages of immersion cycle hints that immersive experience requires more high-level, abstract objectives.
Moreover, the model emphasizes the importance of desires which take up the most of topics. These desires can be interpreted as a summation of experiences which could be called the essence of game. In the traditional model of education, these aspects are easily overlooked. Although the emergence of video games teaches educators that immersion cycle needs more specific desires or experiences. If they are open-minded, they will look through these desires list to find good implications for their curriculum.
6. Conclusion
By applying statistical approach to making a model, more rigorous and reproducible model is produced. This approach could be applied to various studies. And the point that the model is reproducible means this research can develop by itself as time goes by. If we use newer version of game reviews, it is certain that we would find newer version of topics. For example, as new technologies like augmented reality or virtual reality emerges, new topics which reflect these technologies will be exposed in the reviews. The methodology we offered in the study, can reflect all these changes in trends by using new set of reviews. We suggest this is the unique point of what our research contributes.
Furthermore, conventional psychological and neurophysiological knowledge is used as basis for the model by which the model was developed more robust and concretely. Nevertheless, this is still our study's limitation because we are not experts in the field, so further studies in this direction are expected.
Our research can also lead to more frequent and deeper usage of gamification technique in various fields. We have preceding studies which prove the potential of this technique. Lee and Hung [17] showed that the learners in the group of blended learning achieved the highest scores compared to traditional and fully online groups in an e-Learning course designed for a university income tax law curriculum. Technologies in computer and internet are so pervasive that it is hard to forecast the future of learning environment without these technologies. It would be a natural step ahead if we use gamification skills in designing blended learning courses where educational resources are provided more video game alike. As you know, gamification is popular concept in the educational field.
There is another area where this approach can proceed to. Choi et al. [18] developed a model which shows what knowledge students have and what goals they are trying to achieve in the form of educational game. This means that we can know the exact moment of learning and can collect the data for analysis, which leads to adaptive learning. A study of Goyal et al. [19] is a good example of deciding how well students learned the concepts in the course by analyzing the data collected above. It is certain that this would be a successful approach for students like what Google did in its search business. Briefly speaking, Google's gigantic success comes from their technology which enabled delivering information at the Moment of Truth [20]. Therefore, adaptive learning is discussed so actively in various fields like computer science, artificial intelligence, psychology, and brain science.
Our study can be applied to these prospective branches. It would be practical approaches if we apply the model to existing game or curriculum. During application, the dynamics between critical topics which make immersive experience possible would be understood deeper. SRDG model will provide a base camp for future researches.
Biography
Mookyung Kwak
https://orcid.org/0000-0002-2608-4551
He received B.S. degree in psychology from Yonsei University in 2005, and B.S. de-gree in data science & statistics from Korea National Open University in 2011. He was also conferred M.S. degree in e-Learning from Korea National Open University in 2020. He is currently working as a freelancer mobile app developer. His current research interests are in pushing forward to adapting machine learning to educational field.
Biography
Ji Su Park
https://orcid.org/0000-0001-9003-1131
He received his B.S. and M.S. degrees in Computer Science from Korea National Open University, Korea in 2003 and 2005, respectively, and Ph.D. degrees in Computer Scie-nce Education from Korea University in 2013. He is currently a Professor in Depart-ment of Computer Science and Engineering from Jeonju University in Korea. His research interests are in mobile grid computing, mobile cloud computing, cloud compu-ting, distributed system, computer education, and IoT. He is employed as managing editor of Human-centric Computing and Information Sciences (HCIS) by KIPS SCWRG, The Journal of Information Processing Systems (JIPS) by KIPS. He has received "best paper" awards from the CSA2018 conferences and "outstanding service" awards from CUTE2019 and BIC2020. He has also served as the chair, program committee chair or organizing committee chair at several international conferences including MUE, FutureTech, CSA, CUTE, BIC.
Biography
Jin Gon Shon
https://orcid.org/0000-0002-0540-4640
He received the B.S. degree in Mathematics and the M.S. and Ph.D. degrees in Computer Science from Korea University, Seoul, Korea. Since 1991, he has been with the Department of Computer Science, Korea National Open University (KNOU). He had been researching as Visiting Scholars at State University of New York (SUNY) at Stony Brook, USA, in 1997, at Melbourne University, Australia, in 2004, and Indiana University, USA, in 2013. After serving the Head of Information & Computer Center and the Head of e-Learning Center, Professor Shon had established the Department of e-Learning in KNOU, offering the first master program of e-Learning in Korea, and served as the Chair of the Department until 2010. He had also worked for KNOU as Director of the Digital Media Center, where all of KNOU e-learning contents and TV programs are produced. Since 1991, he has been working as well for the community services, as chairs or members in various committees including a Vice President of Korea Information Processing Systems and a Vice President of e-Learning Society. His research interests are mainly focused on computer networks, modeling & simulation, distributed computing, wireless sensor networks, e-learning, and especially in ITLET (Information Technology for Learning, Education, and Training) as a member of Korean Delegation to ISO/IEC JTC1/SC36 since 2000. He has made presentations in many conferences, and he won a few of Best Paper Awards including the Gold Medal Paper in the 24th AAOU Annual Conference in 2010. He has also published over 40 scholarly articles in the noted journals and written several books on computer science and e-learning.
References
- 1 Newzoo, 2020 (Online). Available:, https://newzoo.com/products/reports/global-games-market-report/
- 2 Y. Hu, J. Boyd-Graber, B. Satinoff, A. Smith, "Interactive topic modeling," Machine Learning, vol. 95, no. 3, pp. 423-469, 2014.doi:[[[10.1007/s10994-013-5413-0]]]
- 3 D. M. Blei, A. Y. Ng, M. I. Jordan, The Journal of Machine Learning Research, vol, 3, pp. 993-1022, 2003.custom:[[[-]]]
- 4 S. W. Kim, J. M. Gil, "Research paper classification systems based on TF-IDF and LDA schemes," Human-centric Computing and Information Sciences, vol. 9, no. 30, 2019.doi:[[[10.1186/s13673-019-0192-7]]]
- 5 D. G. Lee, Y. S. Seo, "Improving bug report triage performance using artificial intelligence based document generation model," Human-centric Computing and Information Sciences, vol. 10, no. 26, 2020.doi:[[[10.1186/s13673-020-00229-7]]]
- 6 F. Zhang, T. Y. Wu, J. S. Pan, G. Ding, Z. Li, "Human motion recognition based on SVM in VR art media interaction environment," Human-centric Computing and Information Sciences, vol. 9, no. 40, 2019.doi:[[[10.1186/s13673-019-0203-8]]]
- 7 X. Tan, "Topic extraction and classification method based on comment sets," Journal of Information Processing Systems, vol. 16, no. 2, pp. 329-342, 2020.custom:[[[-]]]
- 8 Y. Yang, L. Li, Z. Liu, G. Liu, "Abnormal behavior recognition based on spatio-temporal context," Journal of Information Processing Systems, vol. 16, no. 3, pp. 612-628, 2020.custom:[[[-]]]
- 9 Metacritic game (Online). Available:, https://metacritic.com/game
- 10 A. Amory, "Game object model version II: a theoretical framework for educational game development," Educational Technology Research and Development, vol. 55, no. 1, pp. 51-77, 2007.custom:[[[-]]]
- 11 D. King, P. Delfabbro, M. Griffiths, "Video game structural characteristics: a new psychological taxonomy," International Journal of Mental Health and Addiction, vol. 8, no. 1, pp. 90-106, 2010.custom:[[[-]]]
- 12 N. S. Said, "An engaging multimedia design model," in Proceedings of the 2004 Conference on Interaction Design and Children: Building a Community, Baltimore, MD, 2004;pp. 169-172. custom:[[[-]]]
- 13 M. W. Berry, S. T. Dumais, G. W. O’Brien, "Using linear algebra for intelligent information retrieval," SIAM Review, vol. 37, no. 4, pp. 573-595, 1995.doi:[[[10.1137/1037127]]]
- 14 T. Hofmann, "Unsupervised learning by probabilistic latent semantic analysis," Machine Learning, vol. 42, no. 1, pp. 177-196, 2001.doi:[[[10.1023/A:1007617005950]]]
- 15 C. Sievert, K. Shirley, "LDAvis: a method for visualizing and interpreting topics," in Proceedings of the Workshop on Interactive Language Learning, Visualization, and Interfaces, Baltimore, MD, 2014;pp. 63-70. custom:[[[-]]]
- 16 M. Corbetta, G. L. Shulman, "Control of goal-directed and stimulus-driven attention in the brain," Nature Reviews Neuroscience, vol. 3, no. 3, pp. 201-215, 2002.custom:[[[-]]]
- 17 L. T. Lee, J. C. Hung, "Effects of blended e-Learning: a case study in higher education tax learning setting," Human-centric Computing and Information Sciences, vol. 5, no. 13, 2015.doi:[[[10.1186/s13673-015-0024-3]]]
- 18 Y. M. Choi, M. W. Choo, S. A. Chin, "Prototyping a student model for educational games," Journal of Information Processing Systems, vol. 1, no. 1, pp. 107-111, 2005.custom:[[[-]]]
- 19 M. Goyal, D. Yadav, A. Tripathi, "An intuitionistic fuzzy approach to classify the user based on an assessment of the learner's knowledge level in e-learning decision-making," Journal of Information Pro-cessing Systems, vol. 13, no. 1, pp. 57-67, 2017.doi:[[[10.3745/JIPS.04.0011]]]
- 20 J. Lecinski, ZMOT: Winning the Zero Moment of Truth, CA: Google, Mountain, 2011.custom:[[[-]]]