Yuxiang Shan , Gang Yu and Yanghua Gao
Human Identification Based on Gait Representation and Analysis
Abstract: Human identification based on gait analysis is a promising biometric technology that can recognize different individuals by their walking patterns. This study primarily addresses the challenges of gait representation and partial occlusion. Firstly, considering the multi-scale and multi-perspective aspects of gait in practical application scenarios, a novel block collaborative gait representation method is proposed based upon local structures, aiming to enhance the accuracy of identity recognition by integrating information from multiple scales and perspectives. Then, we propose a new gait recognition network that integrates dilated convolutions and the residual mechanism (DCRM). The DCRM network adds dilated convolutional blocks to the residual branch to expand the receptive field without losing resolution, thereby reducing the negative impact of local occlusion on recognition accuracy. Experimental results on two public datasets demonstrated that the proposed approach shows clear advantages over existing gait analysis methods.
Keywords: Block Collaborative Gait Representation , Dilated Convolution , Gait Recognition , Residual Mechanism
1. Introduction
Over the past few decades, gait analysis has received extensive research attention owing to its potential applications in security monitoring. Compared to other biometric technologies, such as face and fingerprint analyses, gait analysis offers the following two advantages: 1) gait samples can be captured from long distances with low resolution, and 2) gait analyses can be performed without the cooperation of targeted individuals [1,2]. Consequently, gait analysis has become an important research task in the field of biometrics and is expected to play a significant role in the development of future security technologies.
Researchers have successfully employed numerous deep learning technologies for gait analysis and recognition. Traditional gait recognition methods can be roughly divided into two categories: model-based and appearance-based [3]. Model-based methods utilize the skeletal structure of the human body in high-resolution gait images for modeling and achieve personal identification by extracting the traveling trajectories of the subject. In contrast, appearance-based methods rely solely on silhouette maps obtained from low-resolution gait images and classify the observed object by identifying the distinguishing feature information. While potentially more accurate, this approach may suffer from the limitations of low-resolution gait images, such as noise and incomplete information, leading to errors in object identification [4]. Therefore, it is important to consider the limitations of the input data and incorporate additional information to provide a more comprehensive understanding of identified objects.
To address the challenges of gait representation and partial occlusion, this study introduces a new appearance-based gait recognition framework for human identification. The main contributions of this work are summarized as follows:
& centerdot; A novel block collaborative gait representation (BCGR) method is proposed to address the multi-scale and multi-perspective challenges of gait in practical application scenarios, with the aim of improving the accuracy of identity recognition by integrating information from multiple scales and perspectives.
& centerdot; A new gait-based human identification network was developed by integrating dilated convolutions and the residual mechanism (DCRM). This network reduces the negative impact of local occlusion on recognition accuracy by adding dilated convolutional blocks to the residual branch, thereby expanding the receptive field without losing resolution.
& centerdot; Extensive experiments have been conducted on two open-accessed gait datasets, with results demonstrating that the proposed methods are highly efficient and effective in accurately recognizing human gait patterns. The experimental results also demonstrate the robustness of the proposed methods to various noise and variations in gait data.
The rest of this paper is organized as follows. Section 2 reviews existing gait analysis and recognition methods, and Section 4 presents a detailed discussion of the proposed gait-based human identification framework. Next, Section 4 describes the comparative experiments conducted on two public gait datasets and presents an analysis of the experimental results. Finally, Section 5 concludes the paper.
2. Related Work
As a promising biometric feature, gait has received widespread attention from researchers in fields such as video security monitoring, identity authentication, and health assessment [5,6]. Wang and Yan [3] introduced a gait recognition method that combines the nonlinear dimensionality reduction of gait manifolds with the temporal features of gated recurrent units. Chen et al. [7] used multiple direction gait generation networks to generate new walking images, thereby augmenting the open-accessed dataset with more training data for multidirectional gait identification. Specifically, their approach constructs some generators for each gait pair from existing datasets. In [8], a new gait identification method using convolution special networks was proposed, which utilizes a novel gait representation as training data so that all images pass by the proposed structure to extract the entire feature. Wen and Wang [9] proposed a multidirectional gait identification method with a residual recurrent network to obtain internal gait characteristics and perform human identification. This framework accounts for the temporal correlation of human posture during walking by inputting randomly sampled gait representations, and utilizes the residual network to optimize the obtained characteristic map.
Wang et al. [10] addressed the challenge of fully utilizing the structural features and relationships between key points in human pose estimation by studying and estimating the pose sequences of martial artists using grid convolutional encoding neural networks. Specifically, they used a grid to segment each image, roughly locate key points of the human body, and subsequently locate these key points more accurately based on the offset position output from the grid. In [11], a modified identification model using Gabor filters was introduced for human identification, which inserts a Gabor-filter-based walking characteristic module into a traditional convolutional neural network (CNN) to measure the similarity between different walking postures. Chao et al. [12] treated walking postures as a set and combined many walking images by model. Based on the perspective of this depth set, their proposed method was not affected by frame arrangement and could combine more walking images obtained in different scenes, including those observed from different perspectives, irrespective of bagging. In [13], a walking posture recognition method that uses ensemble learning was developed to generate more training data using given contour sequences and use different hyperparameters to build and train the primary classifiers of a CNN. Wan et al. [14] presented an omni-domain feature extraction network that utilizes an inter-frame sampling approach to capture joint dynamic changes. Mehmood et al. [15] proposed a dual-stream network for human gait recognition, which uses features from grey space as input and processes temporal spatial features through genetic algorithms. Huang et al. [16] proposed a condition-adaptive graph convolution network that used a joint-specific filter learning module to produce sequence-adaptive filters at the joint level.
However, despite significant advances in the accuracy of gait recognition, these methods still face challenges in terms of sample diversity and extracting effective target features. To address these challenges, this paper proposes a new gait-based human recognition method that integrates the dilated convolution and residual mechanisms. The proposed network was designed to expand the receptive field without losing resolution by adding dilated convolutional blocks to the residual branch, thereby reducing the negative impact of local occlusion on recognition accuracy.
3. Proposed Gait-based Human Identification Method

As shown in Fig. 1, the proposed gait-based human identification network is built upon a two-branch CNN structure. Initially, input gait energy images pass through the BCGR layer and are processed into feature maps containing local block information. Subsequently, the information is further processed by normal and dilated convolutional operation sequences. The normal convolutional branch uses three convolutional layers with 3 & times; 3, 5 & times; 5, and 7 & times; 7 cores, while the dilated convolutional branch uses three 3 & times; 3 convolutional kernels with respective dilation rates of 1, 2, and 5. Finally, based on the fused information of the two processing branches, a softmax layer is used for human identification. The number of neurons in the softmax layer is determined by the number of individuals included in the dataset and is manually adjusted as a hyperparameter in the model.
3.1 Block Collaborative Gait Representation
According to the edge optimization principle of AdaBoost, the collaborative representation algorithm for multi-scale blocks integrates the classification results of different scale blocks, thereby improving the algorithm's robustness to scale changes. This principle, which is based on the idea of “information integration at the edge of the network,” enhances the overall performance of AdaBoost by combining the insights and information of different-scale blocks. Consequently, the algorithm is able to better recognize and classify the features of input data, leading to improved accuracy and efficiency. We combined the local structure method with the multi-scale block collaborative representation classification algorithm to transform the single sample recognition problem into a multi-sample recognition problem with certain robustness to scale. Furthermore, we formulated a novel BCGR method to address the multi-scale and multi-perspective problems that characterize practical application scenarios involving gait by integrating information from multiple scales and perspectives. The proposed BCGR method represents gait data as a collection of blocks, which are then collaboratively represented using the multi-scale block collaborative representation classification algorithm. This allows for the integration of diverse information sources, enabling the identification of complex patterns and relationships within gait data. The effectiveness of the proposed method was demonstrated through various experiments, where it outperformed existing methods in terms of recognition accuracy and robustness to scale.
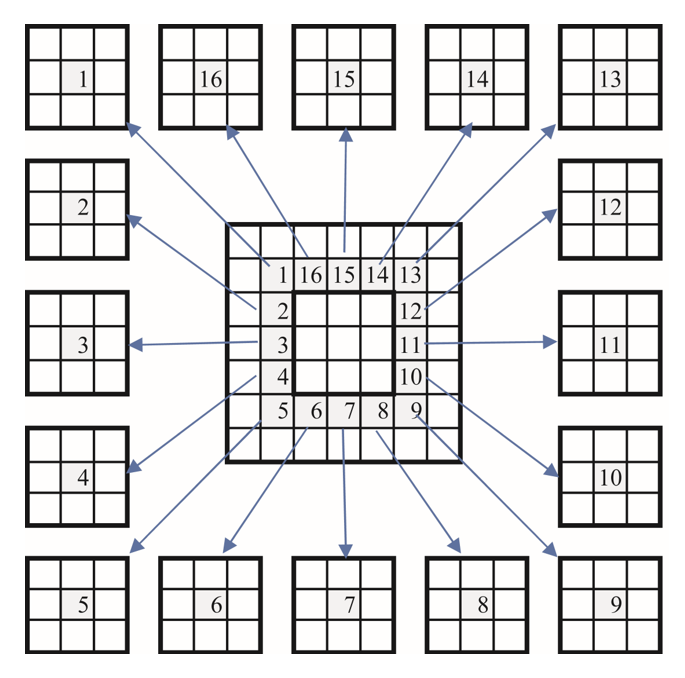
To illustrate the local structure as illustrated in Fig. 2, three types of neighborhood structures are defined in each gait image, each of which forms a completely symmetric neighborhood set within a square area with a side length of E. Here, P denotes the number of nearest neighbor pixels.

For the i-th pixel in the neighborhood set & Phi;, consider designating the j-th pixel as the central pixel of the M & times; M local block. Of the pixels comprising this block, each pixel forms an n-dimensional local block vector [TeX:] $$F_j^i, j=1, \ldots, P, n=M^2 .$$ Similarly, the central pixel i corresponds to a local block of the same size, represented by the vector [TeX:] $$F_0^i.$$ Therefore, for the i-th pixel in the image, all local blocks [TeX:] $$F_j^i(j=1, \ldots, P)$$ form a local block centered at that pixel. Fig. 3 illustrates a local structure consisting of a central block and 16 neighboring blocks of size [TeX:] $$M^2=3 \times 3=9,$$ all of which contribute to a local block of size 7 & times; 7=49.
Local blocks that overlap and are clustered in a small local structure are highly similar. To simplify the analysis, we assume all sub blocks within the same local area to belong to the same linear space. This assumption allows us to represent the local structure between the central block and its neighboring blocks using a linear approximation, especially when the central block can be approximated linearly through the neighborhood block. This approach simplifies the analysis and provides a more accurate representation of the local structures in gait images.
3.2 Gait-based Human Identification
Dilated convolution is a convolutional approach designed to address a challenge in image semantic segmentation where down-sampling reduces image resolution and information loss. Dilated convolution sets a dilation rate for each related module to calculate the similarity of different samples when conducting each convolution operation. The normal dilation rate is set to 1, which can extend the perception range under the same calculation conditions. By creating holes to extend the reception range, an improved 3 & times; 3 convolution kernel can function s a 5 & times; 5 kernel with a dilation rate of 2. We implemented dilated convolution operations in one branch and constructed a new gait-based human identification network that integrates DCRM, reducing the negative impact of local occlusion on recognition accuracy by adding dilated convolutional blocks to the residual branch, and thereby expanding the receptive field without losing resolution, as shown in Fig. 1. By introducing residual mechanisms, the correlation between gradients and losses is improved, thereby enhancing the learning ability of the model and alleviating the problem of degradation.
Given the inherent variability of the receptive field and number of units, the proposed two-branch feature enhancement module uses three 3 & times; 3 convolutions for the dilated convolutional branch, and its equivalent convolutional kernel size is:
where d is the dilation rate; k is the original size of the convolutional kernel, and [TeX:] $$k_d$$ is the corresponding equivalent kernel size.
Because the lack of correlation between the sparse sampling input of the dilated convolution operation and data from a long distance impacts the final gait recognition results, we adopted a two-branch structure that incorporates an additional ordinary convolutional branch. This convolutional branch only uses 3 & times; 3 and 7 & times; 7 convolutional layers, and does not include pooling layers. Notably, we overlaid the BatchNormal and ReLU layers after the convolutional layers of the two branches. The BatchNormal layer is used to normalize the results of activations from the previous layer, enhancing the convergence of gradient descent and stabilizing the network during training. The ReLU layer sets the output values of some neurons to zero, which results in network sparsity, reducing the interdependence between parameters and mitigating the occurrence of overfitting.
4. Experiments
To evaluate the effectiveness of the proposed framework, we conducted several experiments using the CASIA-B and OU-ISIR-LP datasets. The CASIA-B dataset consists of multi-view gait images from 124 persons. For each person, gait samples were collected from 11 perspectives (0, 18, 36, ..., 180 degrees) and under three walking conditions (normal conditions, wearing a coat, carrying a package), as shown in Fig. 4. The OU-ISIR-LP dataset consists of people walking on the ground, surrounded by two cameras with a speed of 30 frames per second and resolution of 640 & times; 480 pixels. The dataset is basically distributed in the form of contour sequences, which have been registered and normalized to a size of 88 & times; 128 pixels, as shown in Fig. 5.


4.1 Block Collaborative Gait Representation
The experimental platform adopts a GPU computing gn6i Alibaba Cloud server configured with 4vCPU, 15 GiB of memory, and a NVIDIA T4 graphics card. The operating system is Ubuntu 20.04, and the integrated development environment uses Python 3.8 and PyCharm 2002.3.2 Professional Edition.
To objectively evaluate the performance of the proposed human identification network, we used precision (Pre), recall (Rec), and the mean of average precision (mAP) as performance indicators, defined as follows:
where TP is the number of positive samples correctly identified as positive, FP is the number of negative samples misclassified as positive, FN is the number of positive samples misclassified as negative, N represents the total number of categories, and [TeX:] $$A P_i$$ represents the mean accuracy of the i-th class. Precision represents the accuracy of identifying as a positive sample, whereas recall describes the proportion of positive samples correctly identified. Precision and recall are inversely proportional, and each indicator must be maximized to achieve optimal performance. mAP takes each category of AP separately and calculates the average of all AP categories, representing a comprehensive measure of the average accuracy of detected targets.
We adopted the k-fold cross-validation technique in the experiment. The original training dataset was divided into k subsets, and we trained the model over k iterations to obtain k performance estimates. In each iteration, we used one validation fold to evaluate the proposed model, with the remaining k–1 folds used to train the model.
4.2 Experiments on the CASIA-B Dataset
In the experiments on the CASIA-B dataset, five existing methods were used as comparative baselines: 1) EnsembleLearning [10], a gait recognition method based on ensemble learning; 2) GF-CNN [8], a modified CNN based on Gabor filters; 3) ResLSTM [6], a gait classification framework based on a residual recurrent neural network; 4) CBAN [5], a gait classification approach that uses a convolutional block attention mechanism; and 5) GaitManifold [3], a gait-based pedestrian recognition framework that combines the nonlinear dimensionality reduction of gait manifolds. In terms of dataset usage, we used all contour images of 124 individuals. Each type of sample was divided using a 9:1 ratio to construct the training and validation sets. In the segmentation of training and validation samples, cross-validation was utilized to ensure the fairness and effectiveness of the testing.
From the results listed in Table 1, our method improved mAP@0.5, precision, and recall by 2.7%, 5.6%, and 4.8%, respectively, compared to the worst-case scenario. Specifically, in terms of precision, the proposed method significantly outperformed all five baselines, with a 2.1% improvement over the relatively well-performing EnsembleLearning and ResLSTM methods. In terms of recall, although the GaitManifold method performed the best among the baselines, our method also achieved a slight improvement of 0.2%. In terms of mAP, which represents a comprehensive indicator, our method also achieved improvements of 0.5% to 2.7% over the baselines. In summary, the experimental results in Table 1 indicate that our method successfully improves the identification of targets from gait data.
Table 1.
| Method | Precision | Recall | mAP@0.5 |
|---|---|---|---|
| EnsembleLearning [13] | 90.5 | 89.0 | 91.7 |
| GF-CNN [11] | 87.0 | 89.3 | 90.1 |
| ResLSTM [9] | 90.5 | 86.5 | 91.4 |
| CBAN [8] | 90.0 | 91.0 | 92.3 |
| GaitManifold [3] | 90.2 | 91.1 | 91.9 |
| Proposed | 92.6 | 91.3 | 92.8 |
This enhancement in performance can be attributed to two major improvements in the proposed network structure:
& centerdot; Using dilated convolution as a branch of the recognition network, we obtain a larger receptive field under the same feature map, thereby obtaining more dense data. Furthermore, using dilated convolution instead of down- or up-sampling can effectively preserve the spatial features of images without information loss.
& centerdot; The two branch structure with different convolutional characteristics obtains multi-scale and multi-angle gait features, which is conducive to exploring the inherent differences in the walking postures of individuals.
4.3 Experiments on the OU-ISIR-LP Dataset
To validate the effectiveness of the proposed network on a larger dataset, an additional comparative experiment was conducted on the OU-ISIR-LP dataset, which encompasses gait data from 4,016 participants. As baselines, we retained the five methods from the previous experiment. All samples collected from four perspectives were allocated between training and validation datasets at a 9:1 ratio. In the segmentation of training and validation samples, the same cross-validation was employed to ensure the fairness of testing.
The experimental results shown in Table 2 reflect significant improvements in precision, recall, and mAP@0.5 compared to the baselines. In terms of precision, the proposed method achieved improvements of 0.8% and 5.5% compared to the best- and worst-performing baseline, respectively. In terms of recall and mAP@0.5, our method achieved improvements of 0.2% and 0.5%, respectively, compared to the best-performing baseline, along with corresponding improvements of 4.7% and 2.7% over the worst-performing baseline.
Furthermore, the performance of each method appears to have decreased when compared to the experimental results in Table 1. This can be attributed to the fact that 4,016 participants are represented by OU-ISIR-LP, whereas only 124 participants are represented by CASIA-B. The substantial increase in the total number of categories in the classification problem impacts classification accuracy.
Table 2.
| Method | Precision | Recall | mAP@0.5 |
|---|---|---|---|
| EnsembleLearning [13] | 88.6 | 87.2 | 89.8 |
| GF-CNN [11] | 85.2 | 87.4 | 88.2 |
| ResLSTM [9] | 88.9 | 84.7 | 89.5 |
| CBAN [8] | 88.1 | 89.1 | 90.4 |
| GaitManifold [3] | 88.3 | 89.2 | 90.0 |
| Proposed | 90.7 | 89.4 | 90.9 |
4.4 Ablation Experiments
To evaluate the contribution of each component of the proposed network, we conducted ablation experiments. From Table 3, the dilated convolution can be associated with greater improvement effects than the normal convolutional structure. Using a single convolutional branch alone, the dilated convolution outperforms the normal convolution by 1.8%, 1.2%, and 2.6% in terms of precision, recall, and mAP@0.5, respectively. When combined with BCGR, dilated convolution yields respective improvements of 1.6%, 1.2%, and 1.3%. In addition, after extracting features through BCGR and integrating two types of convolutions for processing, notable improvements were made in all three indicators.
5. Conclusion
In this paper, we present a novel gait-based human identification method. First, a new BCGR method was designed to solve the multi-scale and multi-perspective problems of gait in practical application scenarios. Then, a novel gait recognition network was developed by integratingDCRM, aiming to reduce the negative impact of local occlusion on recognition accuracy by adding dilated convolutional blocks to the residual branch, thereby expanding the receptive field without losing resolution. Extensive experiments on two open-access gait datasets demonstrate that the proposed network has clear advantages over existing gait recognition methods.
However, the occlusion issue has not been considered within the scope of this study. In future work, we will further investigate gait recognition problems under occlusion and complex backgrounds to promote the use of relevant models and algorithms in practical scenarios.

Biography
Gang Yu
https://orcid.org/0009-0008-0001-0854
He graduated from the School of Computer Science and Technology of Zhejiang University in 2011 with a Master of Engineering degree. He is currently a senior engineer of Information Center of China Tobacco Zhejiang Industrial Co. Ltd. His research interests include signal processing, pattern recognition, and artificial intelligence.
Biography
Yanghua Gao
https://orcid.org/0009-0005-4517-886X
He obtained a master's degree from the School of Computer Science and Technology at Zhejiang University in 2010. Currently, he is a senior engineer of Information Center of China Tobacco Zhejiang Industrial Co. Ltd. His research interests include digital image processing, computer graphics and artificial intelligence.
References
- 1 A. Sepas-Moghaddam and A. Etemad, "Deep gait recognition: a survey," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 1, pp. 264-284, 2023. https://doi.org/10.1109/TPAMI.2022.3151865doi:[[[10.1109/TPAMI.2022.3151865]]]
- 2 J. N. Mogan, C. P. Lee, and K. M. Lim, "Advances in vision-based gait recognition: from handcrafted to deep learning," Sensors, vol. 22, no. 15, article no. 5682, 2022. https://doi.org/10.3390/s22155682doi:[[[10.3390/s22155682]]]
- 3 X. Wang and W. Q. Yan, "Human identification based on gait manifold," Applied Intelligence, vol. 53, no. 5, pp. 6062-6073, 2023. https://doi.org/10.1007/s10489-022-03818-4doi:[[[10.1007/s10489-022-03818-4]]]
- 4 J. Amin, M. A. Anjum, M. Sharif, S. Kadry, Y . Nam, and S. Wang, "Convolutional Bi-LSTM based human gait recognition using video sequences," Computers, Materials & amp; Continua, vol. 68, no. 2, pp. 2693-2709, 2021. https://doi.org/10.32604/cmc.2021.016871doi:[[[10.32604/cmc.2021.016871]]]
- 5 T. Chai, A. Li, S. Zhang, Z. Li, and Y . Wang, "Lagrange motion analysis and view embeddings for improved gait recognition," in Proceedings of the IEEE/CVF Conference on Computer Vision And Pattern Recognition, New Orleans, LA, USA, 2022, pp. 20217-20226. https://doi.org/10.1109/CVPR52688.2022.01961doi:[[[10.1109/CVPR52688.2022.01961]]]
- 6 M. A. A. Faisal, M. E. Chowdhury, Z. B. Mahbub, S. Pedersen, M. U. Ahmed, A. Khandakar, et al., "NDDNet: a deep learning model for predicting neurodegenerative diseases from gait pattern," Applied Intelligence, vol. 53, no. 17, pp. 20034-20046, 2023. https://doi.org/10.1007/s10489-023-04557-wdoi:[[[10.1007/s10489-023-04557-w]]]
- 7 X. Chen, X. Luo, J. Weng, W. Luo, H. Li, and Q. Tian, "Multi-view gait image generation for cross-view gait recognition," IEEE Transactions on Image Processing, vol. 30, pp. 3041-3055, 2021. https://doi.org/10.1109/TIP.2021.3055936doi:[[[10.1109/TIP.2021.3055936]]]
- 8 X. Wang and S. Hu, "Visual gait recognition based on convolutional block attention network," Multimedia Tools and Applications, vol. 81, no. 20, pp. 29459-29476, 2022. https://doi.org/10.1007/s11042-022-12831-1doi:[[[10.1007/s11042-022-12831-1]]]
- 9 J. Wen and X. Wang, "Cross-view gait recognition based on residual long short-term memory," Multimedia Tools and Applications, vol. 80, no. 19, pp. 28777-28788, 2021. https://doi.org/10.1007/s11042-021-11107-4doi:[[[10.1007/s11042-021-11107-4]]]
- 10 Y . Wang, P . Liu, L. Feng, and L. Wang, "Posture estimation & amp; posture sequence recognition for martial artists," Human-centric Computing and Information Sciences, vol. 13, article no. 30, 2023.custom:[[[-]]]
- 11 J. Wen, "Gait recognition based on GF-CNN and metric learning," Journal of Information Processing Systems, vol. 16, no. 5, pp. 1105-1112, 2020. https://doi.org/10.3745/JIPS.02.0143doi:[[[10.3745/JIPS.02.0143]]]
- 12 H. Chao, K. Wang, Y . He, J. Zhang, and J. Feng, "GaitSet: cross-view gait recognition through utilizing gait as a deep set," IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 7, pp. 34673478, 2022. https://doi.org/10.1109/TPAMI.2021.3057879doi:[[[10.1109/TPAMI.2021.3057879]]]
- 13 X. Wang and K. Yan, "Gait classification through CNN-based ensemble learning," Multimedia Tools and Applications, vol. 80, no. 1, pp. 1565-1581, 2021. https://doi.org/10.1007/s11042-020-09777-7doi:[[[10.1007/s11042-020-09777-7]]]
- 14 J. Wan, H. Zhao, R. Li, R. Chen, and T. Wei, "Omni-domain feature extraction method for gait recognition," Mathematics, vol. 11, no. 12, article no. 2612, 2023. https://doi.org/10.3390/math11122612doi:[[[10.3390/math11122612]]]
- 15 A. Mehmood, J. Amin, M. Sharif, and S. Kadry, "Human gait recognition by using two stream neural network along with spatial and temporal features," Pattern Recognition Letters, vol. 180, pp. 16-25, 2024. https://doi.org/10.1016/j.patrec.2024.02.010doi:[[[10.1016/j.patrec.2024.02.010]]]
- 16 X. Huang, X. Wang, Z. Jin, B. Yang, B. He, B. Feng, and W. Liu, "Condition-adaptive graph convolution learning for skeleton-based gait recognition," IEEE Transactions on Image Processing, vol. 32, pp. 47734784, 2023. https://doi.org/10.1109/TIP.2023.3305822doi:[[[10.1109/TIP.2023.3305822]]]